
Datafortrolighed i sprogteknologi: Sikkerhed for regulerede brancher
- 27. mar.
- 7 min læsning

Mange virksomheder bruger stadig Google Translate til at oversætte følsomme dokumenter, selvom det er i direkte konflikt med GDPR. I pharma, jura og finans er konsekvenserne ikke blot juridiske bøder, men tab af fortrolige patientdata, lækage af uindgivne patenter og brud på NDA-aftaler. Denne guide giver dig et klart overblik over, hvilke teknologier der faktisk lever op til kravene, hvad lovgivningen kræver i 2026, og hvilke konkrete trin du skal tage for at sikre compliant oversættelse i din organisation.
Indholdsfortegnelse
Vigtigste Pointer
Punkt | Detaljer |
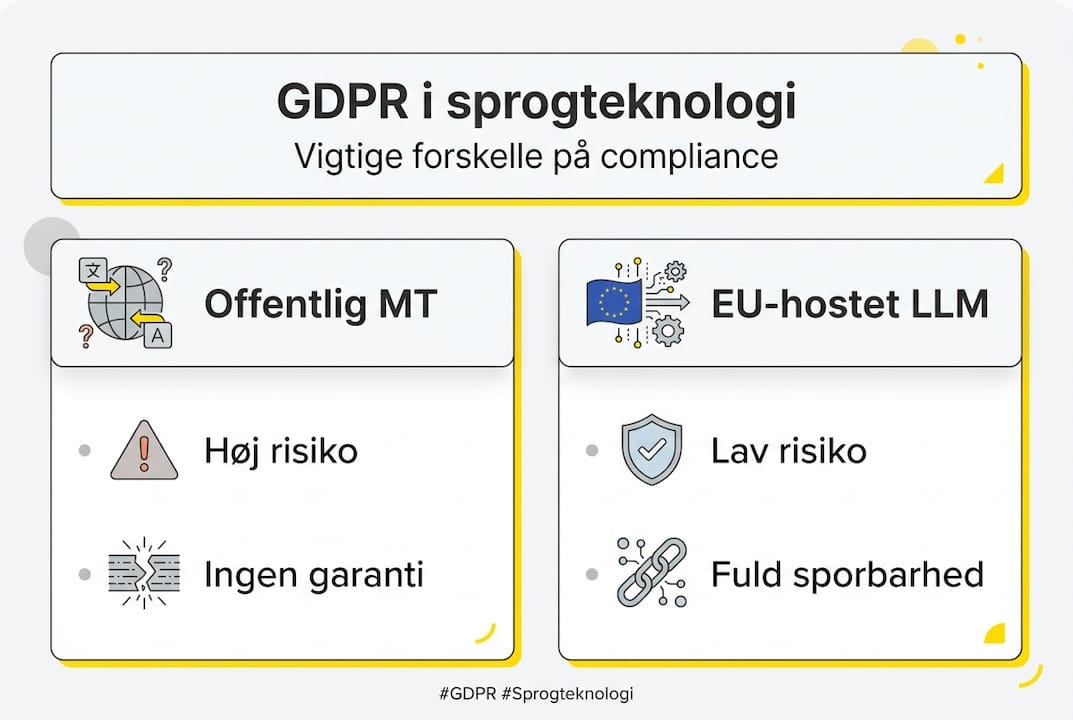
Offentlig MT er risikabel | Google Translate og lignende overholder ikke branchekrav eller GDPR for fortrolige dokumenter. |
EU-regler kræver mere | GDPR og AI Act stiller høje krav til sikkerhed, dataminimering og gennemsigtighed i sprogteknologi. |
AI+Human-model er standard | Menneskelig kvalitetssikring sammen med AI er uundværligt for compliance i regulerede sektorer. |
Vælg EU-soveræne løsninger | Dansk- eller EU-hostede LLMs øger datasikkerheden, præcisionen og undgår amerikanske risici. |
Dokumenter og test alt | Kontrol af leverandører, dokumentation og løbende test er nøglen til databeskyttelse. |
Hvorfor datafortrolighed er altafgørende i sprogteknologi
Når en medarbejder kopierer et klinisk forsøgsresultat ind i et offentligt oversættelsesværktøj, forlader dataene virksomhedens kontrol øjeblikkeligt. Offentlige MT-tjenester (maskinoversættelse) som Google Translate gemmer inputdata og anvender dem til at forbedre deres modeller. Det er ikke en teknisk detalje. Det er et databrud.
Konsekvenserne er målbare. GDPR-bøder kan nå op på 4% af global omsætning eller 20 millioner euro, alt efter hvad der er størst. For en stor pharmavirksomhed kan det betyde hundredvis af millioner i sanktioner for ét enkelt brud.
Regulerede sektorer har særlige krav til dokumentation og sporbarhed. Det er ikke nok at oversætte korrekt. Du skal kunne bevise, at processen var sikker, at data ikke forlod godkendte systemer, og at en kvalificeret fagperson har godkendt outputtet. Offentlige MT-løsninger leverer ingen af disse garantier.
Kulturelt og sprogligt bias er en yderligere risiko, som ofte overses. Modeller trænet primært på engelsksprogede data håndterer dansk fagsprog og juridiske nuancer markant dårligere. Acceptraten for dansk-trænede modeller er op til 2x højere end for generiske modeller, hvilket direkte påvirker præcisionen i regulerede dokumenter.
De primære risici ved brug af offentlig MT i regulerede sektorer:
Datalækage: Inputdata gemmes og bruges til modeltræning
GDPR-brud: Manglende lovlig behandlingshjemmel og formålsbegrænsning
Terminologifejl: Ingen håndhævelse af godkendt fagterminologi
Ingen sporbarhed: Ingen dokumentation for oversættelsesprocessen
Kulturelt bias: Fejlfortolkning af dansk/nordisk fagsprog og kontekst
“En oversættelsesfejl i et medicinsk dokument er ikke en sproglig fejl. Det er en patientsikkerhedsrisiko.”
For at forstå de fulde implikationer af databeskyttelse i oversættelse er det nødvendigt at se på, hvad lovgivningen konkret kræver af teknologi og leverandører.
De juridiske krav: GDPR, EU AI Act og sektorregulering
GDPR stiller krav om lovlighed, formålsbegrænsning, dataminimering og ansvarlighed ved al behandling af personoplysninger. Det gælder også oversættelse. Når du sender et dokument med patientdata eller finansielle oplysninger til en ekstern tjeneste, er det databehandling, og du skal have en gyldig hjemmel og en underskrevet databehandleraftale (DPA).
GDPR-compliance for LLM-udbydere kræver specifikt, at udbydere overholder principper om lovlighed, dataminimering, formålsbegrænsning og ansvarlighed. Ingen offentlig MT-tjeneste opfylder disse krav som standard.
EU AI Act tilføjer et ekstra lag for høj-risiko sektorer. AI Act klassificerer visse AI-systemer som høj-risiko, herunder systemer anvendt i sundhedsvæsen, juridiske processer og finansielle beslutninger. For disse kræves ekstra transparens, dokumentation og menneskelig kontrol.
Kravene til en compliant leverandør kan opsummeres i fire punkter:
Underskrevet DPA: Databehandleraftale der specificerer formål, opbevaringstid og sikkerhedsforanstaltninger
ISO 27001-certificering: Dokumenteret informationssikkerhedsstyring
EU-hosting: Data må ikke behandles på servere uden for EU uden særskilt hjemmel
Ingen data-retention til træning: Dine dokumenter må aldrig bruges til at forbedre modellen
Professionelt tip: Bed altid din leverandør om at dokumentere, præcis hvor dine data behandles og opbevares. Hvis svaret er uklart, er det et rødt flag.
For en detaljeret gennemgang af GDPR og oversættelsestjenester er det vigtigt at forstå, at reglerne ikke kun gælder selve oversættelsen, men hele den teknologiske infrastruktur bag.
Hvordan avanceret sprogteknologi lever op til compliance
Valget af teknologi er ikke blot et spørgsmål om kvalitet. Det er et spørgsmål om lovlighed. Der er en fundamental forskel på offentlige cloud-løsninger og private eller on-premise LLM-systemer (Large Language Models, dvs. store sprogmodeller).

Private eller on-premise LLM-løsninger anbefales frem for amerikanske cloudtjenester for virksomheder med GDPR-forpligtelser. Det skyldes, at data i private systemer aldrig forlader din eller leverandørens kontrollerede infrastruktur.
Kriterium | Offentlig MT (fx Google Translate) | Privat/EU-hostet LLM |
GDPR-compliance | Ikke garanteret | Ja, med DPA |
Dataopbevaring | Ja, til træning | Nej |
ISO 27001 | Nej | Ja |
EU-hosting | Nej | Ja |
Terminologihåndhævelse | Nej | Ja |
Menneskelig QA | Nej | Ja (AI+HUMAN) |
Sporbarhed | Ingen | Fuld dokumentation |
Kryptering er en anden ikke-forhandlingsbar faktor. AES-256-kryptering (en industristandard for databeskyttelse) under transport og i hvile er minimumskravet for følsomme dokumenter. Kombineret med ISO 27001-certificering og en lukket infrastruktur sikrer det, at data ikke kan tilgås af uvedkommende.
Menneskelig review er ikke valgfri i regulerede sektorer. En AI+HUMAN kvalitetssikringsproces sikrer, at en fagspecialist, fx en jurist eller en medicinsk fagperson, validerer outputtet. Det er denne kombination af teknologisk præcision og menneskelig ekspertise, der adskiller compliant oversættelse fra hurtige, usikre løsninger.
Professionelt tip: Spørg din leverandør, om de kan dokumentere formatbevaring. Regulerede dokumenter som EU-ansøgninger og kliniske protokoller har præcise formatkrav, og fejl her kan forsinke godkendelsesprocesser med måneder.
Særlige risici og faldgruber: Bias, datalækage og US vs. EU-løsninger
En risiko, der sjældent diskuteres åbent, er memorization. Store sprogmodeller kan utilsigtet reproducere fragmenter af de data, de er trænet på. Hvis en model er trænet på fortrolige dokumenter, kan dele af dem dukke op i output til andre brugere. Det er ikke en hypotetisk risiko. Det er en dokumenteret egenskab ved LLM-arkitektur.
Brug af US-baserede LLMs indebærer risiko for bias og manglende GDPR-compliance. Modeller udviklet og hostet uden for EU er underlagt anden lovgivning, herunder regler der kan forpligte udbydere til at give myndigheder adgang til data uden varsel til den europæiske kunde.
For dansk og nordisk fagsprog er problemet endnu mere konkret. Dansk/nordisk trænede modeller er nødvendige for compliance og kulturel sikkerhed. En model trænet primært på engelsk vil fejlfortolke juridiske termer, der har præcis betydning i dansk ret, men ingen direkte ækvivalent på engelsk.
Risikoområde | US-baseret LLM | EU-suveræn LLM |
Memorization af fortrolige data | Høj risiko | Lav risiko |
Kulturelt bias | Markant | Minimal |
Juridisk eksponering (GDPR) | Høj | Lav |
Præcision på dansk fagsprog | Lav | Høj |
Dataadgang for myndigheder | Mulig uden varsel | EU-reguleret |
Edge cases er særligt kritiske i regulerede dokumenter. Sjældne fagtermer, kontekstafhængige udtryk og sektorspecifik terminologi håndteres markant bedre af modeller, der er trænet og valideret til sikrede oversættelsesmetoder. En generisk model vil gætte. En specialiseret model vil anvende den godkendte terminologi.
Professionelt tip: Undersøg altid, om din leverandørs AI-model er trænet på data fra din sektor, og om den håndhæver din virksomheds godkendte terminologidatabase. Det er forskellen på en oversættelse og en compliant oversættelse.
Praktiske trin: Sådan sikrer du compliant oversættelse med sprogteknologi
At vælge den rette leverandør kræver mere end at sammenligne priser og leveringstider. Det kræver en systematisk gennemgang af sikkerhed, certificeringer og processer. Her er de konkrete trin:
Verificér ISO 27001 og SOC 2: Leverandører skal have ISO 27001, SOC 2 og ingen data-retention til træning. Bed om dokumentation, ikke blot forsikringer.
Kræv underskrevet DPA: Ingen oversættelse af personoplysninger uden en gyldig databehandleraftale.
Bekræft EU-hosting: Spørg specifikt, hvilke servere og datacentre der anvendes, og i hvilke lande.
Gennemfør DPIA for høj-risiko sager: En DPIA (Data Protection Impact Assessment, dvs. en konsekvensanalyse for databeskyttelse) er lovpligtig ved behandling af særlige kategorier af data.
Kræv AI+HUMAN-workflow: Al reguleret dokumentation skal gennemgå menneskelig review af en fagspecialist med dokumenteret kompetence.
Stil krav om reviewer-logs: Dokumentation af, hvem der har reviewet hvad og hvornår, er afgørende ved audit.
Den operationelle virkelighed er, at oversættelse for regulerede industrier kræver en struktureret tilgang til leverandørvalg. Virksomheder, der ikke dokumenterer deres oversættelsesprocesser, risikerer ikke blot bøder. De risikerer at miste godkendelser, kontrakter og tillid.
Et veldokumenteret workflow for kvalitetssikring reducerer risikoen markant og giver dig den sporbarhed, der kræves ved regulatoriske inspektioner.
Professionelt tip: Test din leverandørs terminologihåndhævelse med en kontroloversættelse af et dokument med kendte fagtermer, inden du indgår en aftale. Hvis outputtet afviger fra din godkendte terminologidatabase, er løsningen ikke egnet til regulerede dokumenter.
Få professionel rådgivning og compliant oversættelse
AD VERBUM kombinerer 25 års erfaring med en proprietær AI+HUMAN-model, der er hostet udelukkende på EU-servere og certificeret efter ISO 27001, ISO 17100 og ISO 18587. Det betyder, at dine dokumenter aldrig forlader en kontrolleret, krypteret infrastruktur, og at en fagspecialist altid validerer outputtet.
Vores AI-drevne oversættelser er bygget til præcis de krav, du møder i pharma, finans og jura: terminologihåndhævelse, fuld sporbarhed og menneskelig QA ved hvert eneste dokument. Vi tilbyder professionel oversættelse med dokumenteret compliance og specialiserede life sciences oversættelser til kliniske dokumenter og medicinsk udstyr. Kontakt os for en gratis konsultation, og få klarhed over, hvordan din organisation kan opnå fuld GDPR og EU AI Act-compliance i jeres oversættelsesprocesser.
Ofte stillede spørgsmål
Er det sikkert at bruge Google Translate til juridiske eller medicinske dokumenter?
Nej. Offentlige MT-tjenester gemmer data og bruger dem til træning, hvilket udgør et direkte brud på GDPR ved behandling af fortrolige eller personhenførbare oplysninger.
Hvordan vurderer jeg om en sprogteknologi-leverandør er compliance-sikker?
Kontrollér, at leverandøren har ISO 27001, ingen data-retention og underskrevet DPA, samt at data behandles på EU-servere med dokumenteret QA-flow.
Hvilken ekstra fordel får jeg ved brug af dansk/nordisk trænede LLMs?
Acceptraten er op til 2x højere med dansk-trænede modeller, og præcisionen på fagsprog og kulturelle nuancer er markant bedre end ved generiske modeller.
Skal man altid have menneskelig QA ved AI-baseret oversættelse?
Ja. For al reguleret dokumentation er menneskelig review og dokumenteret ansvarlighed et lovkrav, ikke blot en anbefaling. Et AI+HUMAN-workflow er minimumsstandarden.
Anbefaling


