
Hvorfor vælge proprietær LLM til regulerede brancher
- 27. maj
- 8 min læsning

Spørgsmålet om, hvorfor vælge proprietær LLM frem for open source alternativer, stiller mange compliance- og IT-ansvarlige i regulerede brancher sig i dag. Og forvirringen er forståelig. Markedet er fyldt med påstande om, at open source er mere fleksibelt, billigere og mere transparent, mens proprietære løsninger blot låser dig til én leverandør. Sandheden er mere nuanceret. Når din virksomhed håndterer patientdata, juridiske dokumenter eller industrielle sikkerhedsmanualer, handler valget af sprogteknologi ikke om pris alene. Det handler om kontrol, ansvar og præcision.
Indholdsfortegnelse
Vigtigste pointer
Punkt | Detaljer |
Proprietær LLM giver compliance-sikkerhed | Centraliserede, private setups muliggør fuld dokumentation og kontrol, som regulerede brancher kræver. |
Terminologikontrol er afgørende | Proprietære modeller kan instrueres til at følge godkendte gloselister, hvilket NMT-værktøjer ikke pålideligt kan. |
Skjulte omkostninger ved open source | Selvhosting af LLM kræver ML-ingeniører og GPU-infrastruktur, som hurtigt overstiger proprietære API-priser. |
Datasikkerhed er ikke valgfrit | I sundheds- og finanssektoren kan offentlige API-kald til NMT udgøre et direkte brud på GDPR og HIPAA. |
Hybridmodeller kan være pragmatiske | Kombination af proprietær LLM til kritiske opgaver og open source til standardvolumen er en levedygtig strategi. |
Hvad er proprietære LLM’er?
En proprietær LLM er en stor sprogmodel, der udvikles, ejes og distribueres af én organisation, typisk tilgængelig via betalte API’er med definerede serviceniveauaftaler. Du betaler for adgang og ydelse, men får ikke indsigt i modelarkitektur, træningsdata eller vægte. Open source LLM’er derimod frigives med åbne vægte, så enhver kan downloade, tilpasse og hoste modellen selv.
Forskellen er ikke blot teknisk. Det er et spørgsmål om driftsmodel og ansvar.
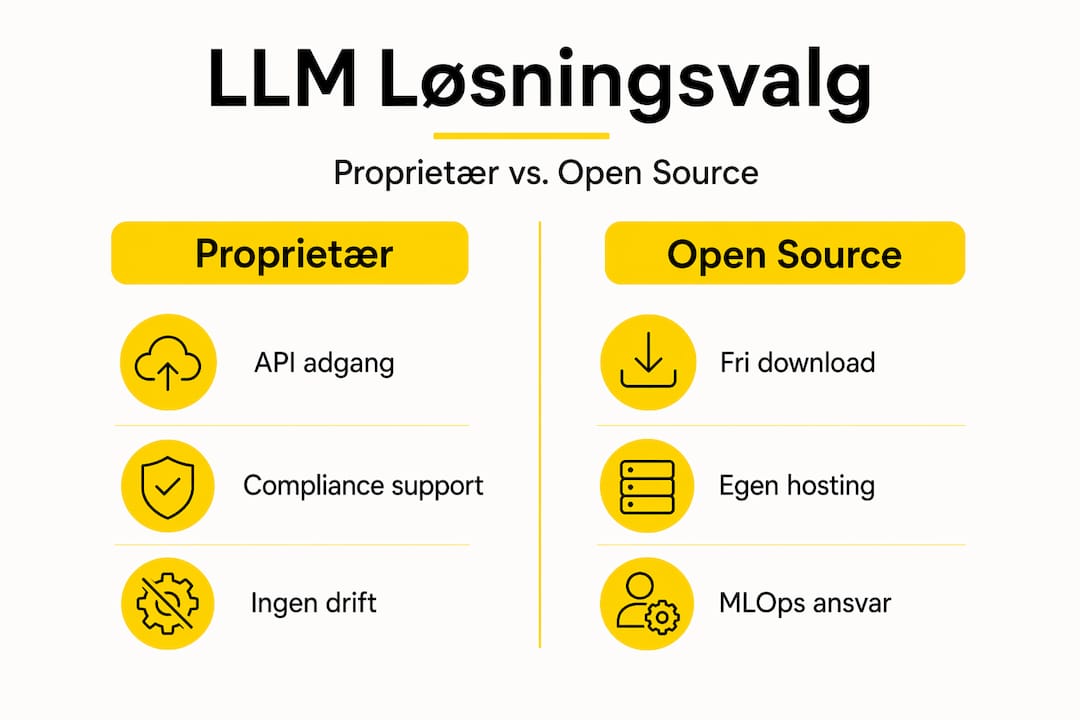
Proprietær versus open source: En direkte sammenligning
Kriterium | Proprietær LLM | Open source LLM |
Adgang | Via API med licens | Fri download og selvhosting |
Transparens | Begrænset indsigt i model | Fuld adgang til kode og vægte |
Support | Dedikeret SLA og support | Communitydrevet, varierende kvalitet |
Infrastruktur | Ingen GPU-krav hos køber | Kræver egne servere eller lejet GPU |
Compliance-dokumentation | Leverandørstyret og struktureret | Selvansvarlig og manuel |
Vendor lock-in risiko | Høj ved dyb integration | Lav, men skaber intern afhængighed |
Implementeringshastighed | Hurtigt via API | Lang implementeringstid ved tilpasning |
Proprietære APIs muliggør funktionelle løsninger på få dage uden GPU-opsætning eller ML-driftshold, hvilket er en konkret fordel for virksomheder uden dyb AI-infrastruktur. Omvendt giver open source fuld datakontrol, men den tekniske byrde er reel.
Det er vigtigt at forstå, at spørgsmålet om proprietær LLM versus open source ikke har ét universelt svar. Det afhænger af din organisations tekniske kapacitet, risikoappetit og regulatoriske forpligtelser.
Datasikkerhed og compliance i regulerede erhverv
Her bliver valget virkelig konkret for virksomheder i Life Sciences, finans og jura. Lad os se på, hvad der faktisk sker, når du sender følsomme data til en sprogmodel.
Offentlige NMT-tjenester som Google Translate eller DeepL er ikke designet til regulerede dataflows. Når en medarbejder indsætter et udkast til en klinisk prøverapport eller et patentdokument i et offentligt oversættelsesværktøj, forlader data virksomhedens kontrollerede miljø. Det er ikke hypotetisk. Det er et dokumenteret brud på GDPR, HIPAA og ofte på NDA-forpligtelser. Datasuverænitet er afgørende i sundheds- og finanssektorer, hvor offentlige API-kald kan udgøre en direkte compliance-risiko.
Proprietære LLM’er, der hostes i private, lukkede cloud-miljøer på EU-servere, løser dette problem strukturelt. Data forlader ikke det kontrollerede miljø. Adgangsstyring, logning og revisionsspor er indbygget.

Hvad compliance faktisk kræver
Her er, hvad professionelle i regulerede brancher bør efterspørge fra enhver LLM-leverandør:
Databehandleraftale (DPA): En juridisk bindende aftale om, hvordan data behandles, opbevares og beskyttes.
ISO 27001-certificering: Bekræfter, at leverandøren har et dokumenteret informationssikkerhedssystem.
Geografisk datalokation: Data skal forblive inden for et defineret juridisk område, typisk EU under GDPR.
Revisionsspor: Fuld logning af, hvem der har adgang til hvilke data hvornår.
Ingen træning på kundedata: Garantien om, at dine dokumenter ikke bruges til at forbedre leverandørens model.
Private LLM-setups muliggør fuld kontrol over token-adgang, compliance-dokumentation og dataflow, hvilket er præcis det mønster, som compliance-afdelinger i regulerede brancher kræver at se dokumenteret.
Professionelt tip: Bed altid din LLM-leverandør om en udfyldt sikkerhedsvurdering i et standardiseret format som ISO 27001-kontrolskemaet, inden du underskriver en aftale. En seriøs proprietær leverandør har det klar til udlevering.
Et typisk eksempel: Et advokatfirma, der lokaliserer kontraktmateriale til klienter i flere lande, kan ikke tillade, at fortrolige forretningsvilkår behandles i en offentlig cloud. Et sundhedsselskab, der oversætter kliniske resultatmål til 20 sprog, kan ikke risikere, at patientidentificerbare oplysninger sendes til en tredjeparts server uden revisionsspor. Proprietær AI-oversættelse beskytter følsomme data effektivt i netop disse scenarier.
Præcision i teknisk oversættelse og lokalisering
Compliance og datasikkerhed er nødvendige betingelser. Men de er ikke tilstrækkelige, hvis selve oversættelseskvaliteten er utilstrækkelig. Her adskiller proprietær LLM-teknologi sig markant fra både ældre MT-systemer og fra generiske NMT-tjenester.
En proprietær LLM kan finjusteres til et specifikt fagdomæne og instrueres direkte i terminologiregler. Det betyder, at modellen ikke bare oversætter ord. Den forstår kontekst og følger din godkendte terminologiliste.
Sådan opnås præcision i praksis
Integration af eksisterende oversættelseshukommelse ™: Den proprietære model indlæser dine tidligere godkendte oversættelser, så konsistens på tværs af dokumenter er garanteret fra første dag.
Terminologidatabaser (TB) som hård begrænsning: Modellen instrueres til altid at oversætte “Device” som “Apparatus” i overensstemmelse med din godkendte gloseliste. NMT-tjenester kan ikke pålideligt overholde sådanne regler.
Domænespecifik finjustering: En proprietær model kan trænes på juridiske, medicinske eller tekniske korpusser, hvilket giver markant bedre semantisk forståelse i komplekse faglige tekster.
AI+HUMAN hybrid validation: Modellens output gennemgås af fageksperter med baggrund inden for det specifikke domæne, der verificerer nøjagtighed, regulatorisk overensstemmelse og kontekstuel nuance.
Proprietære modeller udmærker sig ved komplekse agent-workflows og sikkerhedskritiske anvendelser, præcis de scenarier, som teknisk oversættelse og lokalisering i regulerede brancher udgør.
Den praktiske forskel er tydelig: En NMT-tjeneste, der oversætter “non-toxic” til “toxic” ved at springe negationen over, er ikke et hypotetisk eksempel. Det er en dokumenteret fejltype ved NMT-systemer. I et produktdatablad eller en brugsanvisning for medicinsk udstyr er den fejl ikke blot uacceptabel. Den er potentielt livsfarlig. Lukkede LLM-systemer til sikker oversættelse adresserer netop dette ved at kombinere modellens kontekstforståelse med menneskelig fagekspertise.
Professionelt tip: Når du evaluerer en LLM-løsning til teknisk oversættelse, bør du altid teste med et dokument fra dit eget domæne med bevidste terminologiudfordringer. Bed leverandøren om at vise, hvordan modellen håndterer din godkendte terminologiliste i praksis, ikke blot i teorien.
Økonomi og implementering: Return on investment
En udbredt misforståelse er, at proprietære LLM’er altid er dyrere end open source alternativer. Regnestykket er mere komplekst end som så.
Hvad koster det egentlig?
Faktor | Proprietær LLM (API) | Open source (selvhosting) |
Infrastrukturomkostning | Ingen hardware kræves | GPU-leje kan overstige $4.000 pr. måned |
Personaleomkostning | Minimal, ingen ML-ingeniører nødvendige | Kræver dedikerede ML-ingeniører i drift |
Implementeringstid | Dage via API | Uger til måneder ved tilpasning |
SLA og oppetid | Garanteret ved kontrakt | Selvansvarlig |
Compliance-dokumentation | Leverandørstyret | Kræver intern ressource og juridisk arbejde |
Skalerbarhed | Automatisk ved øget forbrug | Manuel skalering af hardware |
Vedligeholdelse af open source LLM’er kræver betydelig ML-ingeniørindsats, med skjulte omkostninger, der sjældent er synlige ved første øjekast. Det er det klassiske problem med total cost of ownership. Licensomkostningen for open source er nul, men driftsomkostningen er det ikke.
For virksomheder med lav til moderat volumen og uden dedikeret MLOps-kapacitet er proprietære API’er typisk billigere, hurtigere og mere pålidelige fra dag ét. Proprietære APIs giver hurtig time-to-market og reducerer behovet for interne AI-specialister markant.
For virksomheder med meget høj volumen og stærke tekniske teams kan selvhosting af open source modeller på sigt være konkurrencedygtig. Men vejen derhen er lang og ressourcekrævende.
Hvornår bør du vælge proprietær frem for open source?
Valget er et forretnings- og driftsmodelvalg fremfor et rent teknisk. Her er en situationsbaseret guide:
Vælg proprietær LLM, hvis:
Din organisation opererer i en stærkt reguleret branche med dokumentationskrav til AI-brug.
Du ikke har et dedikeret ML-ingeniørteam til at drive og vedligeholde en selvhostet model.
Time-to-market er kritisk, og du har brug for en stabil løsning inden for uger, ikke måneder.
Dine data er følsomme og kræver klare, juridisk bindende garantier om behandling og opbevaring.
Terminologikontrol og konsistens på tværs af store dokumentvolumener er afgørende for kvalitet og compliance.
Overvej open source, hvis:
Du har internt MLOps-kapacitet og ressourcer til at drive infrastrukturen.
Dine use cases er standardiserede med lav risiko, og du behandler ikke fortrolige data.
Du ønsker fuld kontrol over modelarkitekturen og træningsdata.
Du er villig til at acceptere vendor lock-in som en risiko at undgå frem for en driftsrisiko at påtage sig.
En hybrid tilgang kombinerer proprietær LLM til komplekse og sikkerhedskritiske opgaver med open source til standardiserede workloads med høj volumen. Det er en pragmatisk model for større organisationer med differentierede behov.
Mit perspektiv på proprietære LLM’er i praksis
Jeg har fulgt LLM-markedets udvikling tæt og talt med mange compliance- og IT-ansvarlige i regulerede brancher. Og jeg vil sige det direkte: Den mest undervurderede risiko er ikke vendor lock-in. Det er den illusion om kontrol, som open source skaber.
Når en organisation beslutter sig for at selvhoste en open source model til behandling af fortrolige data, påtager den sig et ansvar, som de færreste har kapacitet til at håndtere fuldt ud. Opdateringer til sikkerhedshuller, modeladfærd efter finjustering, revisionsspor til compliance. Alt dette kræver ressourcer, som typisk er undervurderede i de tidlige projektkalkulationer.
Min erfaring er, at de organisationer, der lykkes med proprietær LLM i erhvervslivet, er dem, der tidligt definerer, hvad de faktisk har brug for af kontrol. Ikke maksimal kontrol. Reel, dokumenterbar kontrol. Proprietær AI giver sikkerhed og kontrol for beslutningstagere, der ikke kan tillade sig at gætte.
Det overrasker mig stadig, hvor sjældent virksomheder stiller leverandøren et simpelt spørgsmål: “Kan du give mig et komplet revisionsspor over, hvordan mine data er behandlet?” Et seriøst proprietært setup kan besvare det spørgsmål konkret og dokumenteret. Mange open source selvhosting-projekter kan det ikke, fordi infrastrukturen aldrig er blevet bygget til det formål.
Proprietære modeller klarer sig bedre på de sværeste 10 til 20 procent af reelle produktionsopgaver, og det er præcis de 10 til 20 procent, der har størst konsekvens i regulerede brancher. Fejl i standardtekst er irriterende. Fejl i en medicinsk brugsanvisning eller et juridisk kontraktdokument er noget helt andet.
— Viestarts
AD VERBUM: AI+HUMAN hybrid oversættelse med proprietær LLM
AD VERBUM har i over 25 år leveret professionel oversættelse til virksomheder i Life Sciences, jura, finans og industri. Vores teknologiske kerneprincip er enkelt: proprietær LLM-teknologi, hostet eksklusivt på EU-servere under ISO 27001-certificering, kombineret med fageksperter der gennemgår hvert eneste output. Det er AI-oversættelse med efterredigering på højeste niveau. Ikke NMT med generisk output, men en lukket, kontrolleret sprogmodel, der er instrueret direkte i din terminologi og dine styleguides. Resultatet er professionel oversættelse til virksomheder, der kombinerer hastigheden ved AI-oversættelse med menneskelige fageksperters kvalitetssikring. Se vores branchefokuserede løsninger og find ud af, hvordan AD VERBUM sikrer compliance, datasikkerhed og præcision i dit næste oversættelsesprojekt.
FAQ
Hvad er forskellen på proprietær LLM og open source LLM?
En proprietær LLM er lukket og tilgængelig via licenserede API’er med leverandørstyret support og compliance-dokumentation. En open source LLM frigives med åbne modelværkter, som organisationen selv downloader, tilpasser og driver på egne servere.
Hvorfor bruge proprietær LLM i regulerede brancher?
Proprietære LLM’er i private cloud-miljøer giver den dokumenterbare datasikkerhed, revisionsspor og compliance-garantier, som sundheds-, finans- og juridiske sektorer kræver. Offentlige NMT-tjenester opfylder typisk ikke disse krav.
Er proprietære LLM’er dyrere end open source?
Ikke nødvendigvis. Selvhosting af open source LLM kræver GPU-infrastruktur, der kan overstige $4.000 pr. måned, samt dedikerede ML-ingeniører. For de fleste virksomheder uden MLOps-kapacitet er proprietære API’er billigere i den reelle totale omkostning.
Hvad er vendor lock-in, og er det et problem?
Vendor lock-in betyder, at dyb integration med én proprietær leverandør gør det teknisk og operationelt krævende at skifte. Det er en reel risiko, men den skal vurderes mod den tilsvarende risiko ved at drive kompleks open source infrastruktur internt.
Kan man kombinere proprietær og open source LLM?
Ja. En hybrid model, hvor proprietær LLM anvendes til sikkerhedskritiske og komplekse opgaver og open source til standardiserede workloads med høj volumen, er en praksisnær løsning for større organisationer med differentierede behov og teknisk kapacitet.
Anbefaling


