
GDPR-conforme vertalingen: veilig, nauwkeurig en compliant
- 24 apr
- 7 minuten om te lezen

Zelfs zorgvuldig voorbereide vertalingen lekken regelmatig onbedoeld persoonsgegevens, omdat metadata, verborgen tekstvelden en publieke vertaaltools buiten uw beveiligde omgeving opereren. De gemiddelde kosten van een datalek lopen wereldwijd in de miljoenen, en voor gereguleerde sectoren is de reputatieschade vaak even kostbaar als de boete zelf. GDPR vereist meer dan goede intenties: het vraagt een systematische, aantoonbaar compliant aanpak van elk vertaalproces. Dit artikel laat zien waar de echte valkuilen zitten, welke technologie helpt en hoe u een workflow inricht die zowel juridisch houdbaar als operationeel efficiënt is.
Inhoudsopgave
Belangrijkste Inzichten
Punt | Details |
Meest gemaakte fouten | Onbedoelde metadata en persoonsinformatie lekken veroorzaken het grootste risico bij vertalingen. |
AI heeft grenzen | Technologie helpt, maar menselijke validatie blijft cruciaal voor GDPR-conforme vertalingen. |
Branchespecifieke aanpak | Life Sciences, juridisch en financiële sector moeten elk hun eigen risico-inschatting en workflow hanteren. |
Stapsgewijze workflow noodzakelijk | Een vast proces met intake, risicobeoordeling en certificering borgt juridische compliance. |
Waarom GDPR een uitdaging is voor vertalingen
De meeste compliance-teams focussen op data-opslag en toegangsbeheer, maar vergeten dat het vertaalproces zelf een kritiek risicomoment is. Een document verlaat het beveiligde systeem, passeert een vertaaltool of een externe linguïst, en keert terug. In die keten zitten minstens drie punten waar persoonsgegevens kunnen lekken.
De cruciale rol van GDPR in vertaling wordt in de praktijk structureel onderschat. Denk aan documenten die worden aangeleverd als Word-bestanden: revisiegeschiedenissen, commentaren en verborgen auteursnamen zijn technisch gezien persoonsgegevens. Stuurt u zo’n bestand naar een publieke NMT-tool, dan schendt u de AVG al voordat de vertaling ook maar begint.
Het gaat bovendien verder dan de zichtbare tekst. Volgens praktijkrichtlijnen voor GDPR-conforme vertaalworkflows zijn dit de meest voorkomende, maar minst besproken risicogebieden:
Dataretentie: Vertaalbureaus bewaren bronbestanden soms jaren zonder expliciete bewaarbeleid, wat in strijd is met het opslagbeperkingsbeginsel.
Metadata-exposure: Documenteigenschappen, trackwijzigingen en ingebedde afbeeldingen kunnen namen, locaties of medische codes bevatten.
Cross-border transfers: Vertaling naar of door partijen buiten de EER vereist aanvullende juridische mechanismen, zoals Standard Contractual Clauses (SCC’s, standaardcontractbepalingen voor internationale dataoverdracht).
Gemengde documenten: Teksten die meerdere talen combineren, worden vaak gedeeltelijk verkeerd verwerkt, waardoor context en privacygevoeligheid verloren gaan.
Speciale categorieën data: Gezondheidsgegevens, biometrische gegevens en strafrechtelijke informatie vallen onder Article 9 AVG en vereisen een veel strenger regime.
Bijzondere aandacht verdient de combinatie van cross-border transfers en speciale categorieën data. Een klinisch dossier dat voor vertaling naar een partner buiten de EER wordt gestuurd zonder geldige SCC’s, levert niet één maar twee overtredingen op: onrechtmatige doorgifte én onvoldoende bescherming van bijzondere persoonsgegevens.
U kunt gevoelige data beschermen door al bij de documentintake een risicoclassificatie door te voeren. Zo weet u meteen welk vertaalpad en welk beveiligingsniveau van toepassing zijn, nog voordat een linguïst het bestand opent.
Hoe technologie GDPR-conform vertalen ondersteunt (en waar het tekortschiet)
AI en Natural Language Processing (NLP) bieden reële voordelen bij het detecteren van persoonsgegevens in teksten. Maar de prestaties variëren sterk per taal, en dat is precies het probleem voor Europese organisaties.

Onderzoek naar meertalige PII-detectie (PII staat voor Personally Identifiable Information, ofwel privacygevoelige identificatiegegevens) toont aan dat de F1-score, een maatstaf voor detectienauwkeurigheid, voor Europese talen varieert tussen 0,6 en 0,83. Een F1-score is een getal tussen 0 en 1 waarbij 1 perfecte detectie betekent. In de praktijk betekent een score van 0,6 dat één op de vier persoonsgegevens ongedetecteerd blijft. Voor een medisch dossier of juridisch contract is dat onaanvaardbaar.
Het kernprobleem: de meeste AI-detectietools zijn getraind op Engelstalige data. Nationale identificatienummers zoals een Nederlands BSN, een Duits Personalausweisnummer of een Pools PESEL worden door zulke tools structureel gemist. Bovendien mist context: de naam “Berg” is in een Duits adres een achternaam, maar in een geografische beschrijving een gewoon zelfstandig naamwoord.
| Technologie | PII-detectie (meertalig) | Terminologie-afdwinging | GDPR-compliant | |—|—|—|—| | Publieke NMT (bijv. DeepL) | Laag | Geen | Nee | | Generieke LLM (publieke cloud) | Matig | Beperkt | Nee | | Eigen LLM op EU-servers | Hoog | Volledig instelbaar | Ja |
De conclusie is helder: voor veiligheid in technische vertalingen is AI een waardevol hulpmiddel, maar geen standalone oplossing. Publieke cloudtools verwerken uw data buiten uw eigen omgeving, wat al een schending van de AVG kan zijn. Een privaat, gesloten systeem op EU-servers is de minimumstandaard.
Pro-tip: Vraag uw vertaalpartner niet alleen naar ISO 27001-certificering, maar ook naar de specifieke serverlocatie en het dataretentiebeleid. Als het antwoord vaag is, is dat zelf al een risicosignaal.
Menselijke controle blijft essentieel, juist bij de gevallen die AI het meest waarschijnlijk mist. Een vakspecialist herkent dat “behandeling” in een medische context een andere juridische lading heeft dan in een contractcontext, iets wat geen algoritme betrouwbaar kan garanderen.
Sectoren met verhoogde risico’s en hun vereisten
Niet elke sector kampt met dezelfde uitdagingen, zeker als het gaat om gevoelige data en juridische aansprakelijkheid.
Life Sciences werkt structureel met bijzondere persoonsgegevens: patiëntendossiers, klinische onderzoeksdata, bijwerkingsrapportages. De Medical Device Regulation (MDR) en GCP-richtlijnen (Good Clinical Practice) stellen aanvullende eisen bovenop de AVG. Een verkeerde vertaling van een bijsluiter of een klinische uitkomstmaat is geen administratieve fout, maar een direct risico voor patiëntveiligheid.
Juridische organisaties verwerken contracten, getuigenverklaringen en strafdossiers die vrijwel altijd bijzondere categorieën data bevatten. Voor grensoverschrijdende juridische afdwingbaarheid zijn gecertificeerde of beëdigde vertalingen verplicht. De essentiële punten voor veilige vertalingen in dit segment omvatten ook de correcte behandeling van advocaat-cliëntprivilege in de doeltaal.
Financiële instellingen werken met kredietdossiers, KYC-documenten (Know Your Customer) en risicobeoordelingen. Financiële persoonsgegevens vallen onder speciale categorie data die pseudonimisering vereist. Pseudonimisering betekent dat directe identificatoren worden vervangen door codes, zodat de tekst alleen betekenis heeft voor wie de sleutel bezit.
Sector | Primaire risico | Vereiste maatregel |
Life Sciences | Patiëntidentificatie in klinische data | MDR-compliant workflow, SME-review |
Juridisch | Bijzondere data in dossiers en contracten | Gecertificeerde/beëdigde vertaling |
Financieel | KYC- en kredietdata buiten beveiligde omgeving | Pseudonimisering, ISO 27001-partner |
De keuze van het juiste type juridische vertaaldiensten en compliance hangt direct af van uw sectorprofiel en de gevoeligheidsclassificatie van uw documenten. Generieke vertaaloplossingen voldoen hier simpelweg niet.
Stel per documenttype een risicoklasse vast (laag, midden, hoog).
Koppel aan elke risicoklasse een vaste workflow, inclusief SME-review en pseudonimisering waar vereist.
Documenteer elke stap voor de verwerkingsregistratie onder AVG artikel 30.
Bewezen GDPR-conforme vertaalworkflows: van intake tot oplevering
Een compliant vertaalproces is geen eenmalige actie maar een reproduceerbare workflow. Elke stap moet aantoonbaar zijn, zodat u bij een audit of incident kunt bewijzen dat u de juiste maatregelen heeft genomen.
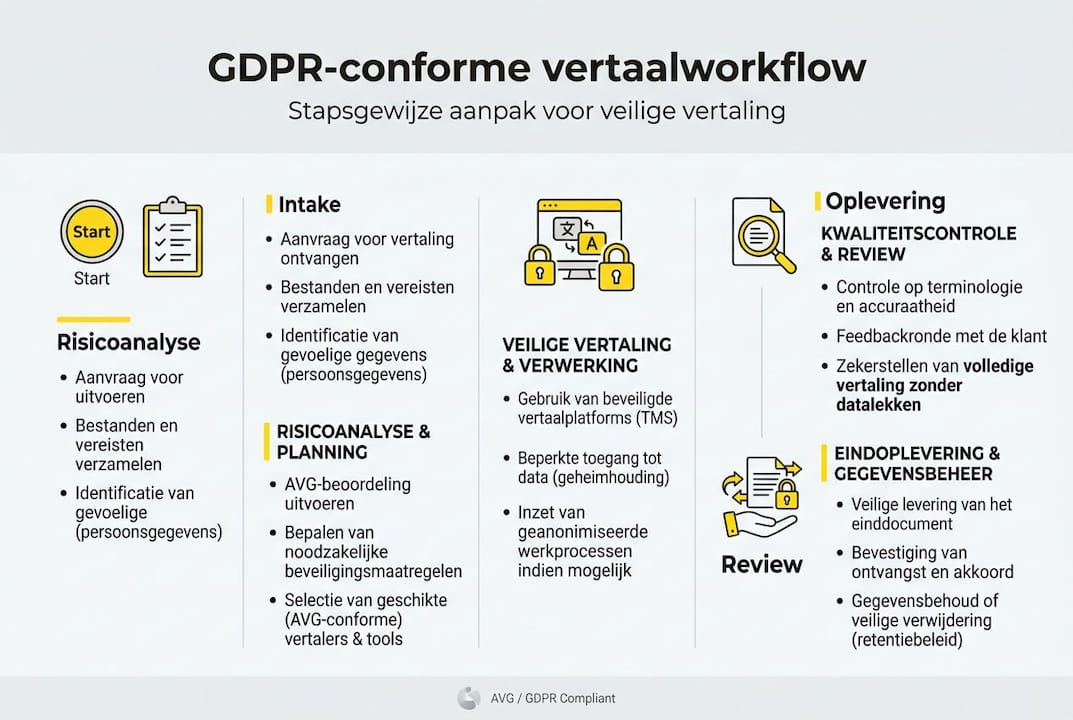
Pro-tip: Behandel uw vertaalworkflow als een verwerkingsactiviteit onder de AVG. Dat betekent: vastleggen wie toegang heeft, waar data opgeslagen wordt, hoe lang het bewaard blijft en op welke rechtsgrond u verwerkt.
Voor high-stakes documenten is een gecombineerde AI+menselijke workflow de erkende standaard voor regulatoire compliance. Zo ziet een bewezen aanpak eruit:
Intake en risicoclassificatie: Bepaal bij ontvangst het documenttype, de aanwezige dataklassen en het toepasselijk regelgevingskader. Bevat het bestand bijzondere persoonsgegevens? Dan geldt een verhoogd regime.
Pseudonimisering vóór vertaling: Vervang directe identificatoren door codes voordat het document de vertaalomgeving ingaat. Dit beperkt schade bij een onverhoopt incident.
Beveiligde verwerking: Gebruik uitsluitend een gesloten, EU-gehoste omgeving. Publieke NMT-tools zijn niet toegestaan voor dit type data. De vertaling wordt gegenereerd door een propriëtaire LLM die uw goedgekeurde terminologiedatabase en stijlgids respecteert.
SME-review door vakspecialist: Een gecertificeerde linguïst met sectorachtergrond valideert terminologische correctheid, contextuele nuance en regulatoire precisie. Dit is het moment waarop subtiele fouten worden onderschept die AI over het hoofd ziet.
Kwaliteitscontrole en certificering: De eindtekst doorloopt een QA-fase conform ISO 17100 en ISO 18587. Waar vereist, wordt een gecertificeerde of beëdigde vertaling opgesteld.
Veilige oplevering en documentatie: Bestanden worden via een versleuteld kanaal geleverd. Alle verwerkingsstappen zijn gedocumenteerd en beschikbaar voor uw compliance-dossier.
Zowel de stappen voor veilig en nauwkeurig vertalen als een volledige compliance checklist voor vertaling helpen u deze workflow intern te verankeren en auditklaar te maken.
Onze visie: waarom menselijk toezicht altijd doorslaggevend blijft
De markt beweegt snel richting volledig geautomatiseerde vertaaloplossingen. Leveranciers beloven hogere snelheid, lagere kosten en voldoende nauwkeurigheid. Voor eenvoudige, niet-gevoelige teksten klopt dat vaak. Maar voor gereguleerde documenten is de redenering gevaarlijk simplistisch.
AI versnelt de detectie van persoonsgegevens en verlaagt de kans op terminologische inconsistentie. Maar het mist stelselmatig nationale en sectorspecifieke nuances, precies de nuances die juridisch het verschil maken. Een algoritme herkent niet dat een bepaalde formulering in een Frans medisch rapport een verwijzing is naar een lokaal zorgprotocol, of dat een specifieke Duits-rechtse juridische term een andere aansprakelijkheidscontext impliceert dan de letterlijke Nederlandse vertaling.
Nog belangrijker: bij een incident of audit is aansprakelijkheid mensenwerk. Een AI-systeem kan geen verantwoording afleggen. De vakspecialist die het document heeft gereviewed wel. Dat is precies waarom wij bij AD VERBUM kiezen voor een onvoorwaardelijk AI+HUMAN model, waarbij menselijk toezicht niet optioneel is maar structureel verankerd in elk proces.
Onze kritiek op “AI-only” aanbieders is concreet: ze verschuiven het risico naar de klant, zonder dat de klant dat beseft. AVG-compliant vertalen vereist aantoonbare menselijke validatie. Wie dat weglaat, levert geen compliance, maar een compliance-illusie.
GDPR-conforme vertaaldienst nodig? Ontdek onze aanpak
De bovenstaande stappen geven u een solide basis, maar de uitvoering vraagt gespecialiseerde expertise, gecertificeerde technologie en aantoonbare compliance-documentatie. Dat is precies waar AD VERBUM in voorziet.
Met 25 jaar ervaring in Life Sciences, juridische en financiële vertaling, ISO 27001-gecertificeerde EU-infrastructuur en een AI+HUMAN workflow met 3.500 vakspecialisten, levert AD VERBUM niet alleen accurate vertalingen maar ook het compliance-bewijs dat u bij een audit nodig heeft. Bekijk onze gespecialiseerde vertaaldiensten of lees meer over onze unieke werkwijze. Neem vandaag nog contact op voor een vrijblijvend adviesgesprek of offerte op maat.
Veelgestelde vragen over GDPR en vertaling
Wat zijn de grootste privacyvalkuilen bij vertalingen?
Metadata en verborgen persoonsgegevens in bestanden vormen het grootste risico op datalekken, vooral bij gevoelige sectoren zoals Life Sciences en juridische dienstverlening.
Zijn AI-vertalingen veilig genoeg voor GDPR?
AI-detectie werkt onvoldoende voor niet-Engelse identificatoren en complexe documentcontexten. Menselijke validatie door een vakspecialist is voor regulatoire compliance niet te omzeilen.
Welke documenttypes vragen gecertificeerde of beëdigde vertalingen?
Juridische documenten, contracten en officiële stukken met persoonsgegevens vereisen doorgaans gecertificeerde of beëdigde vertalingen voor juridische afdwingbaarheid in de doeltaal.
Wat is het belang van pseudonimisering bij vertalen?
Pseudonimisering is verplicht bij speciale categorieën data zoals medische dossiers en financiële gegevens, en beperkt het risico bij een incident tot alleen degenen met de bijbehorende sleutel.
Aanbeveling


