
Machinevertaling vs LLM – Kritische keuzes voor sectoren
- 1 jan
- 6 minuten om te lezen

Elke fout in een gevoelige vertaling kan juridische of medische gevolgen hebben die miljoenen kunnen kosten. In een wereld waar informatiebeveiliging en nauwkeurigheid centraal staan, eisen leidinggevenden in Europese levenswetenschappen en juridische sector absolute zekerheid over hun documenten. Deze introductie laat zien hoe de nieuwste vertaalsystemen, zoals Machine Translation en Large Language Models, nieuwe standaarden zetten voor veiligheid en terminologische precisie.
Inhoudsopgave
Sleutelconclusies
Punt | Details |
Evolutie van vertaaltechnologie | De overgang van Regelgebaseerde Machinevertaling naar Neuraal/LLM-gebaseerde systemen biedt verbeterde contextuele interpretatie. |
Waarde van context en nuances | LLM’s begrijpen niet alleen woorden, maar ook intentie en culturele implicaties, wat cruciaal is voor sectoren zoals gezondheid en recht. |
Data- en documentbeveiliging | Het waarborgen van vertrouwelijkheid en integriteit tijdens het vertaalproces is essentieel om juridische en professionele risico’s te vermijden. |
Integratie van technologie en menselijke expertise | Voor optimale vertalingen is het belangrijk om vertaaltechnologie te combineren met menselijke kwaliteitscontrole. |
Machinevertaling en LLM’s uitgelegd
De wereld van vertaaltechnologie evolueert razendsnel, met Machine Translation (MT) en Large Language Models (LLMs) die de manier waarop we communiceren ingrijpend veranderen. Waar traditionele machinevertaling zich voornamelijk richtte op letterlijke vertalingen, brengen LLMs een nieuw tijdperk van contextueel begrip en diepere linguïstische nuance.
Traditionale machinevertaling werkte met statistische modellen en regel-gebaseerde systemen die vaak moeite hadden met complexe taalstructuren. In tegenstelling daaraan gebruiken LLMs geavanceerde neurale netwerken die taal veel genuanceerder kunnen interpreteren. Ze begrijpen niet alleen woorden, maar ook de context, intentie en subtiele betekenislagen binnen communicatie.
Het grote verschil tussen machinevertaling en LLMs zit in hun vermogen om context te begrijpen. Waar klassieke vertaalsystemen woord-voor-woord vertalen, kunnen LLMs hele zinnen en paragrafen interpreteren, waardoor vertalingen natuurlijker en accurater worden. Dit maakt ze bijzonder waardevol voor sectoren waar precisie cruciaal is, zoals gezondheidszorg, juridische dienstverlening en internationale bedrijfscommunicatie.
Pro-tip: Kies altijd voor een vertaaldienst die niet alleen technologie gebruikt, maar ook menselijke expertise integreert voor de meest nauwkeurige resultaten.
Drie generaties vertaalsystemen vergeleken
De evolutie van vertaaltechnologie kan worden onderverdeeld in drie cruciale generaties, elk met zijn eigen unieke kenmerken en beperkingen. Deze generaties weerspiegelen de voortdurende technologische vooruitgang in ons streven naar nauwkeurige en contextbewuste communicatie.
De eerste generatie, Rule-Based Machine Translation (RBMT), was gebaseerd op gedetailleerde linguïstische regels en woordenboeken. Deze systemen werkten met strikte grammaticale instructies, maar faalden vaak bij complexe zinstructuren en idiomatische uitdrukkingen. De tweede generatie, Statistische Machine Translation (SMT), introduceerde een data-gedreven benadering waarbij vertalingen werden gegenereerd op basis van statistische modellen en grote parallelle tekstcorpora. De derde generatie vertaaltechnologieën bieden een veel geavanceerdere aanpak door gebruik te maken van neurale netwerken en Large Language Models (LLMs).
Moderne LLM-systemen onderscheiden zich door hun vermogen om context te begrijpen, nuances te interpreteren en zelfs culturele implicaties mee te nemen in vertalingen. In tegenstelling tot voorgaande generaties kunnen deze systemen niet alleen woorden vertalen, maar ook de onderliggende bedoeling en emotionele lading van teksten vatten. Dit maakt ze bijzonder waardevol voor sectoren waar precisie en diepgaand begrip cruciaal zijn, zoals juridische documentatie, medische communicatie en internationale bedrijfsvoering.
Hieronder vindt u een vergelijkingstabel van de belangrijkste vertaalsystemen en hun toepassingen:
Generatie vertaalsysteem | Technologie | Typische sectoren | Belangrijkste beperking |
Regelgebaseerd (RBMT) | Linguïstische regels | Overheid, documentatie | Moeite met idiomen en complexe zinnen |
Statistisch (SMT) | Data-gedreven modellen | Financiële sector, grote projecten | Geen diep contextueel begrip |
Neuraal/LLM-gebaseerd | Neurale netwerken, LLM’s | Medisch, juridisch, internationaal | Hoge rekenkracht vereist |
Pro-tip: Kies altijd voor vertaaltechnologie die niet alleen vertalingen produceert, maar ook de context en nuance van de oorspronkelijke tekst begrijpt.
Hoe LLM-technologie terminologie versterkt
De revolutie in vertaaltechnologie wordt gedreven door de unieke mogelijkheden van Large Language Models (LLM’s) om terminologie op een ongekend nauwkeurige manier te begrijpen en te verwerken. Anders dan traditionele vertaalsystemen kunnen LLM’s de diepere context en nuances van vaktermen interpreteren, wat cruciaal is voor precisietoepassingen.
Geavanceerde kwaliteitsbeoordelingsraamwerken voor vertalingen tonen aan hoe LLM’s informatie uit uitgebreide contexten kunnen extraheren, waardoor zij terminologische consistentie kunnen garanderen die ver uitstijgt boven conventionele vertaalmethoden. LLM’s beschikken over het vermogen om gespecialiseerde vaktermen niet alleen letterlijk over te zetten, maar ook hun precieze betekenis en context te begrijpen, ongeacht de complexiteit van de brontekst.
In sectoren zoals gezondheidszorg, recht en techniek, waar terminologische nauwkeurigheid levensbelangrijk is, bieden LLM’s een ongekende meerwaarde. Ze kunnen niet alleen termen consistent vertalen, maar ook de onderliggende semantische nuances herkennen die cruciaal zijn voor een correcte interpretatie. Dit betekent dat gespecialiseerde documenten, zoals medische onderzoeksverslagen of juridische contracten, met veel grotere precisie kunnen worden vertaald.
Pro-tip: Ontwikkel een gedetailleerde terminologische database die als trainingsmateriaal kan dienen voor uw LLM-vertaalsysteem.
Dataveiligheid en compliance bij vertalen
In de complexe wereld van gegevensbescherming vormen vertalingen een kritiek knooppunt waar technologie en wettelijke vereisten elkaar ontmoeten. Dataveiligheid bij vertalingen gaat veel verder dan alleen het beschermen van woorden. Het draait om het veiligstellen van de integriteit, vertrouwelijkheid en beschikbaarheid van gevoelige informatie tijdens het volledige vertaalproces.
De keuze voor een verantwoorde AI-vertaalstack vereist een gelaagde aanpak van beveiligingsmaatregelen. Organisaties moeten niet alleen technische beschermingslagen implementeren, maar ook procedurele waarborgen creëren die voldoen aan strikte privacywetgevingen zoals GDPR, HIPAA en sectorspecifieke compliancestandaarden. Dit betekent dat elke vertaalde zin, elk document en elke gegevensuitwisseling moet worden beschermd tegen ongeautoriseerde toegang, manipulatie of lekken.
Het risico bij onveilige vertalingen is aanzienlijk. In sectoren zoals gezondheidszorg, juridische dienstverlening en financiën kunnen een enkele vertaalfout of datalek verstrekkende gevolgen hebben. Professionele vertaaldiensten moeten daarom niet alleen beschikken over geavanceerde encryptietechnologieën, maar ook over gecontroleerde werkprocessen waarbij menselijke experts de nauwkeurigheid en veiligheid van elke vertaling bewaken.
Pro-tip: Kies altijd voor vertaaldiensten met gecertificeerde ISO 27001 informatiebeveiliging en aantoonbare compliance-trackrecords.
Dit overzicht toont hoe verschillende databeschermingsmaatregelen bijdragen aan veilige vertalingen:
Maatregel | Praktisch resultaat | Relevante regelgeving |
Encryptie van data | Voorkomt ongeautoriseerde toegang | GDPR, HIPAA |
Menselijke kwaliteitscontrole | Minimaliseert vertaalfouten | ISO 27001, sectorstandaarden |
Gelaagde toegangscontrole | Beschermt gevoelige documenten | Financiële en gezondheidswetgeving |
Praktische risico’s voor gevoelige documenten
Gevoelige documenten vormen een bijzonder kritische categorie in vertaalprocessen, waarbij elke kleine fout of datalek verstrekkende consequenties kan hebben. Vertrouwelijkheid is niet langer een optie, maar een absolute noodzaak voor organisaties die werken met medische dossiers, juridische contracten of financiële rapporten.
In sectoren met strikte regelgeving liggen de risico’s bij onzorgvuldige vertalingen bijzonder hoog. Compliance-workflows voor veilige vertalingen zijn essentieel om potentiële juridische en professionele risico’s te minimaliseren. Een verkeerde vertaling kan leiden tot medische fouten, juridische geschillen of zelfs financiële sancties, waardoor de consequenties veel verder gaan dan alleen communicatieve misverstanden.
De praktische risico’s concentreren zich rond drie centrale aspecten: informatiebeveiliging, terminologische nauwkeurigheid en wettelijke conformiteit. Organisaties moeten niet alleen beschikken over geavanceerde vertalingstechnologieën, maar ook over gecontroleerde processen die elke vertaalde zin kritisch evalueren. Dit vereist een combinatie van AI-technologie en menselijke expertise om de hoogst mogelijke nauwkeurigheid te garanderen.
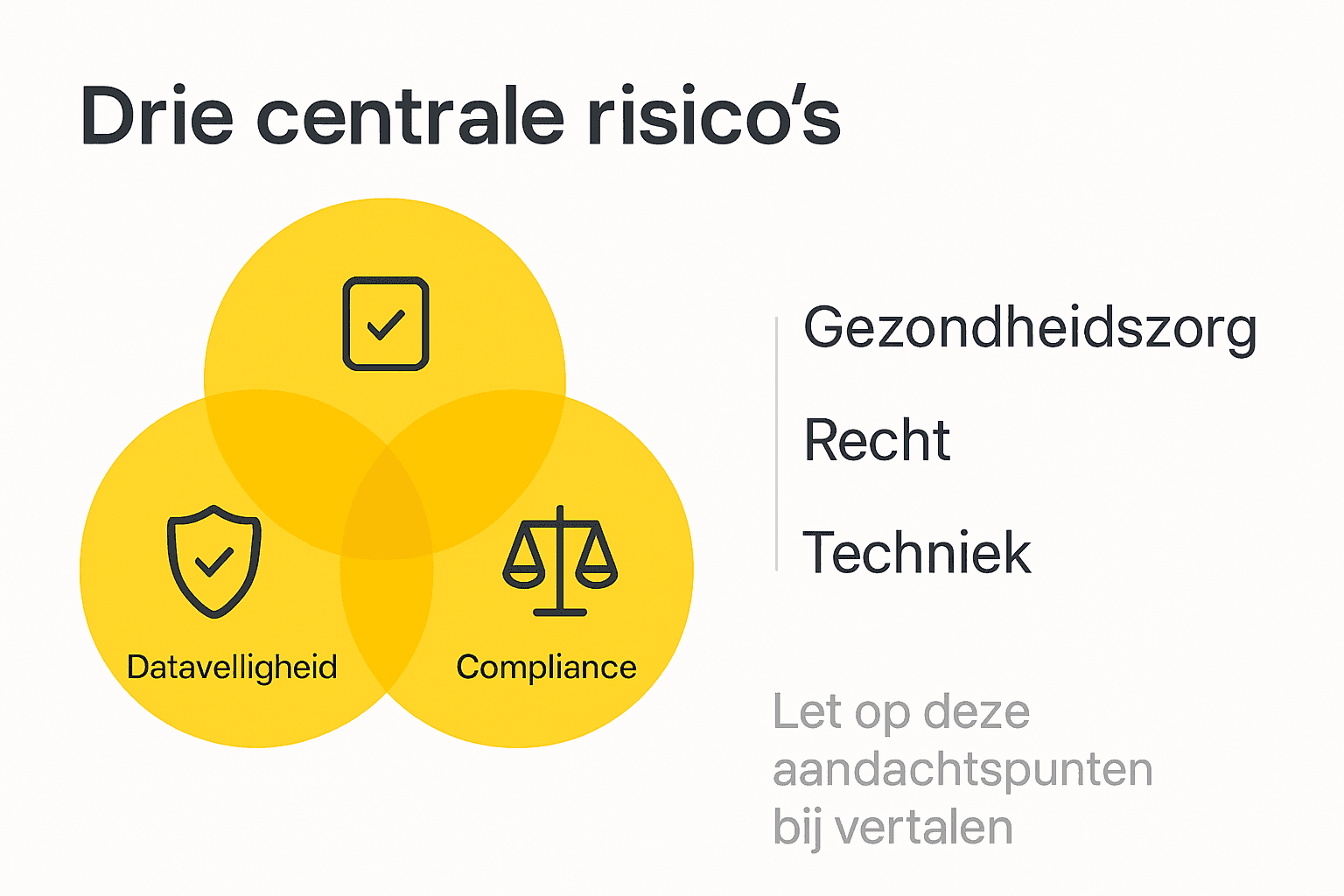
Pro-tip: Ontwikkel een gedetailleerd protocol voor documentclassificatie en vertaalrisicobeoordeling voordat gevoelige documenten worden overgedragen.
Kies voor maximale nauwkeurigheid en veiligheid met AD VERBUM’s AI+HUMAN vertaaloplossingen
De uitdagingen rondom machinevertaling versus LLM-technologie zijn duidelijk: het waarborgen van terminologische precisie, contextueel begrip én strikte dataveiligheid. Dit artikel benadrukt hoe sectoren zoals gezondheidszorg, recht en financiële dienstverlening alleen kunnen vertrouwen op vertaaloplossingen die niet alleen technisch geavanceerd zijn maar ook aan de hoogste compliance-eisen voldoen.
Bij AD VERBUM begrijpen we dat het vertalen van complexe, gevoelige documenten méér vereist dan een letterlijke omzetting. Ons Proprietary AI Ecosysteem met eigen LLM-gebaseerde AI werkt exclusief binnen een beveiligde EU-infrastructuur en wordt aangevuld door een netwerk van meer dan 3.500 vakinhoudelijke linguïsten. Deze combinatie garandeert:
Volledige naleving van GDPR, HIPAA en ISO 27001
Strikte toepassing en handhaving van specifieke terminologie
Een unieke AI+HUMAN workflow die zorgt voor contextueel correcte en foutloze vertalingen
Wilt u weten hoe onze geavanceerde vertaaldiensten de risico’s van onveilige machinevertalingen aanpakken en uw gevoelige documenten beschermen? Bezoek onze website en ontdek de toekomst van vertalen voor gereguleerde industrieën via AD VERBUM. Of lees meer over onze benadering van de juiste AI-vertalingstechnologie die voldoet aan de strengste kwaliteits- en veiligheidsnormen.
Neem vandaag nog contact op en versnel uw vertaalprocessen met vertrouwen dankzij de betrouwbare, veilige en nauwkeurige oplossingen van AD VERBUM.
Veelgestelde Vragen
Wat zijn de belangrijkste verschillen tussen machinevertaling en LLM’s?
Machinevertaling is gebaseerd op statistische modellen of linguïstische regels, terwijl LLM’s gebruikmaken van neurale netwerken om context en nuance te begrijpen. Dit maakt LLM’s vaak nauwkeuriger en beter geschikt voor complexere teksten.
Voor welke sectoren zijn LLM’s het meest waardevol?
LLM’s zijn bijzonder waardevol voor sectoren zoals gezondheidszorg, juridische dienstverlening en internationale bedrijfscommunicatie, waar precisie en contextueel begrip cruciaal zijn.
Hoe verbetert LLM-technologie de terminologie in vertalingen?
LLM’s kunnen vaktermen beter begrijpen en interpreteren, wat zorgt voor consistenter en nauwkeuriger vertalen, vooral in gespecialiseerde velden zoals techniek en geneeskunde.
Wat zijn de veiligheidsmaatregelen die nodig zijn bij het gebruik van vertaaltechnologie?
Het is belangrijk om encryptie, kwaliteitscontrole door mensen en gelaagde toegangscontrole te implementeren om gevoelige informatie te beschermen en te voldoen aan regelgeving zoals GDPR en HIPAA.
Aanbeveling


