
Vertrouwelijke AI-vertaling: veilig, compliant en efficiënt
- 3 mei
- 9 minuten om te lezen

Eén verkeerd geconfigureerde vertaaltool en uw meest vertrouwelijke patientgegevens, octrooiaanvragen of juridische contracten belanden op een externe server. In gereguleerde sectoren is dat geen hypothetisch risico, het is een reëel compliance-incident met directe juridische en financiële consequenties. Dit artikel legt precies uit wat vertrouwelijke AI-vertaling inhoudt, waarom publieke AI-tools structureel tekortschieten voor uw sector, welke technologieën beschikbaar zijn en hoe u beveiligde vertaalprocessen concreet integreert in uw organisatie.
Inhoudsopgave
Belangrijkste Inzichten
Punt | Details |
AI-vertaling vereist veiligheid | Gebruik nooit onveilige publieke AI-platformen voor vertrouwelijk materiaal. |
Geen standaardoplossing | De beste AI-aanpak verschilt per sector en type content; kies op basis van uw behoeften. |
Nieuwe technologie op komst | Privacy-preserving en encrypted AI-oplossingen worden steeds toegankelijker. |
Proces is net zo belangrijk als technologie | Training, workflow-integratie en controle zijn noodzakelijk ondanks de beste tech-keuzes. |
Wat is vertrouwelijke AI-vertaling precies?
Vertrouwelijke AI-vertaling is het gebruik van kunstmatige intelligentie voor het vertalen van gevoelige documenten, waarbij de vertrouwelijkheid van de brondata gedurende het gehele proces gewaarborgd blijft. Dat klinkt eenvoudig, maar in de praktijk is het een fundamenteel andere architectuur dan gewone machinevertaling.
Bij een standaard vertaaltool zoals Google Translate of DeepL verloopt het vertaalproces via externe, publieke cloudservers. Uw tekst verlaat uw organisatie, wordt verwerkt op infrastructuur die u niet beheert, en keert terug als vertaling. Voor een receptentip of een toeristische tekst: geen probleem. Voor een concept-arbeidsovereenkomst, een klinisch onderzoeksrapport of een octrooispecificatie is dat een ernstig beveiligingslek.
Gevoelige data kent vele vormen in gereguleerde sectoren:
Patientgegevens en medische dossiers (beschermd onder GDPR en HIPAA)
Octrooiaanvragen en technische specificaties (beschermd als intellectueel eigendom)
Juridische contracten en processtukken (vertrouwelijk onder beroepsgeheim)
Financiële rapporten en interne audits
Regelgevingsdossiers voor toezichthouders zoals de EMA of FDA
De precisie en veiligheid van documentvertaling zijn in deze sectoren geen optionele kwaliteitsverbetering, ze zijn een wettelijke verplichting.
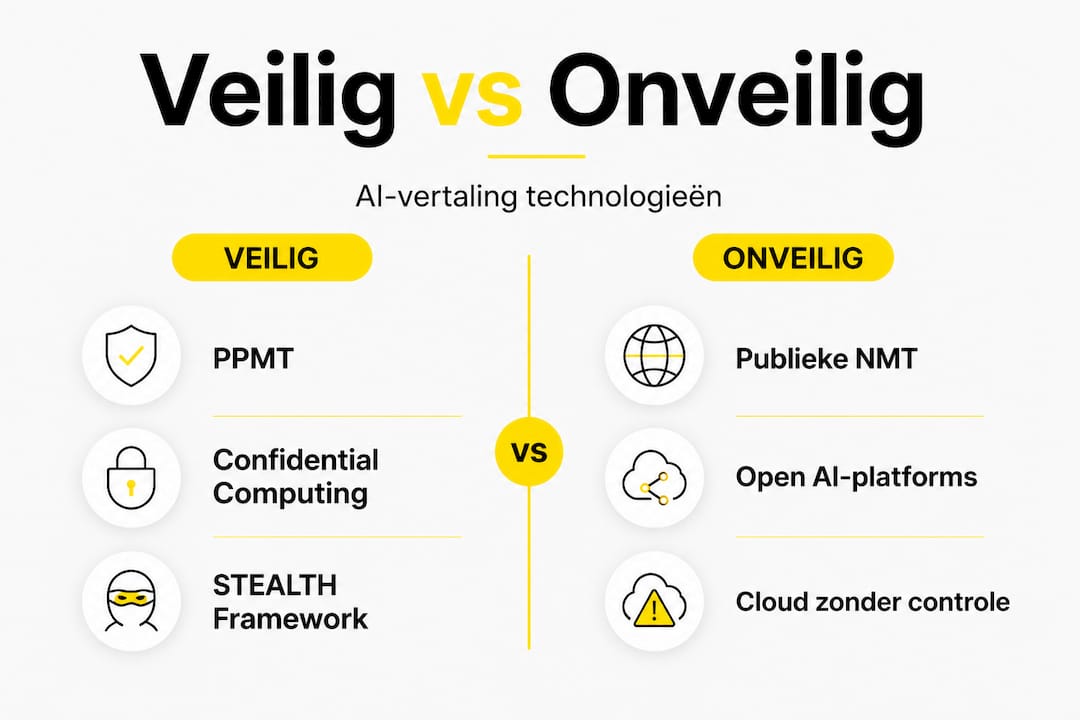
Publieke AI-platforms brengen twee structurele risico’s mee die in de literatuur goed gedocumenteerd zijn. Ten eerste zijn er datalekken: tekst die u invoert in een publieke tool kan gebruikt worden voor modeltraining of kan toegankelijk zijn voor derden. Ten tweede zijn er hallucinations, waarbij AI-modellen feitelijk onjuiste informatie produceren die vloeiend en overtuigend klinkt. Een model dat “niet-toxisch” vertaalt als “toxisch” in een veiligheidsinformatieblad is geen theoretisch scenario, het is een gedocumenteerd risicotype. Onderzoek naar governance bij AI-vertaling laat zien dat proprietary en hybride systemen structureel superieur zijn aan publieke oplossingen voor compliance-kritische toepassingen, terwijl frontier LLMs beter presteren dan gespecialiseerde NMT in juridische contexten, mits goed geconfigureerd.
Gespecialiseerde en hybride systemen zijn juist vanwege deze tekortkomingen ontwikkeld. Ze combineren een gesloten, beveiligde AI-omgeving met menselijke vakexperts die de output controleren. De workflow voor veilige AI-vertaling in dergelijke systemen zorgt ervoor dat uw data nooit een beveiligde omgeving verlaat en dat terminologiefouten worden onderschept voordat ze een document bereiken.
Belangrijkste technologieën en strategieën voor veilig vertalen
Om beter te begrijpen welke keuzes bedrijven hebben, behandelen we de verschillende technologieën en beveiligingsstrategieën die momenteel beschikbaar zijn voor vertrouwelijke AI-vertaling.

Privacy-preserving machine translation (PPMT) is een opkomende categorie waarbij het vertaalproces zo is ingericht dat de inputdata nooit in leesbare vorm de beveiligde grens overschrijdt. Technieken als encrypted embeddings zorgen ervoor dat zelfs de AI zelf de brondata niet “ziet” in haar originele vorm. Dit is relevant voor scenario’s waarbij u vertalingen wilt uitbesteden zonder daadwerkelijk vertrouwelijke tekst te delen.
Confidential computing gaat een stap verder. Bedrijven als NVIDIA en Fortanix bieden hardware-gebaseerde beveiligingsoplossingen waarbij berekeningen plaatsvinden in een zogenoemde trusted execution environment (TEE), een afgeschermde enclave op het niveau van de processor. Zelfs de cloudprovider zelf heeft geen toegang tot de data die daarbinnen wordt verwerkt. Confidential computing voor zorginnovatie toont aan hoe deze aanpak specifiek voor gevoelige gezondheidszorgdata een veilige verwerking mogelijk maakt zonder in te leveren op de rekenkracht van moderne AI.
Topology-preserving encrypted embeddings, zoals die van het STEALTH-framework, bieden een methode om semantische relaties tussen woorden en zinnen te bewaren in een versleutelde ruimte. Dit maakt het mogelijk om AI-vertaalmodellen te trainen of te gebruiken zonder dat de onderliggende tekst ooit ontsleuteld hoeft te worden.
Hieronder een overzicht van de belangrijkste technologieën en hun kenmerken:
Technologie | Beveiliging | Prestaties | Geschikt voor |
Publieke NMT (Google, DeepL) | Laag | Hoog | Niet-gevoelige content |
On-premise LLM | Zeer hoog | Hoog (met GPU) | Alle gereguleerde sectoren |
Cloud LLM (privaat) | Hoog | Zeer hoog | Enterprise compliance |
PPMT met encrypted embeddings | Zeer hoog | Gemiddeld | Farmaceutisch, juridisch |
Confidential computing (TEE) | Maximaal | Afhankelijk van hardware | Healthcare, defensie |
Het debat tussen on-premise en cloud-gebaseerde AI is genuanceerd. On-premise systemen geven volledige controle over de data en de infrastructuur, maar vereisen aanzienlijke investeringen in hardware, beheer en updates. Privécloud-oplossingen op dedicated EU-servers bieden vergelijkbare databescherming met minder beheerslast. Voor de meeste organisaties in gereguleerde sectoren is een privécloud-oplossing met ISO 27001-certificering en GDPR-compliance de meest praktische en kostenefficiënte keuze.
De beste veilige AI-vertaaltools voor enterprise gebruik combineren doorgaans meerdere van deze benaderingen: een proprietary LLM in een privécloud, aangevuld met terminologiedatabases en menselijke review door vakexperts.
Pro-tip: Vraag bij elke leverancier expliciet naar de data residency van uw documenten. Specifiek: op welke servers worden uw documenten verwerkt, in welk land staan die servers, en worden uw teksten gebruikt voor modeltraining? Als deze vragen niet met een duidelijk “nee” worden beantwoord op het laatste punt, is de oplossing niet geschikt voor gereguleerde toepassingen.
Prestaties en betrouwbaarheid: hoe goed werkt vertrouwelijke AI-vertaling?
Nu u een beeld hebt van de technologieën, bekijken we hoe goed deze vertrouwelijke AI-systemen daadwerkelijk presteren in praktijktoepassingen.
De meest gebruikte maatstaf voor vertaalkwaliteit is de BLEU-score (Bilingual Evaluation Understudy). Een BLEU-score vergelijkt de machinaal gegenereerde vertaling met een referentievertaling van een menselijke expert, uitgedrukt als een getal tussen 0 en 100. Een score boven de 30 geldt in de literatuur als “bruikbaar”, een score boven de 50 als “uitstekend”. Maar de BLEU-score meet alleen oppervlakkige overeenkomst met de referentietekst. Hij meet niet of een term juridisch correct is, of een dosering klinisch verantwoord is vertaald, of een veiligheidsinstructie de juiste imperatief gebruikt.
Actueel onderzoek levert scherpe cijfers op. Een gespecialiseerd farmaceutisch taalmodel, het PhT-LM, behaalde een BLEU-4 score van 36.018 op regelgevingsteksten, een sectorspecifiek resultaat dat publieke NMT-systemen consequent niet halen op dit type gespecialiseerde content. Nog relevanter: een experiment met meer dan 11.000 zinnen uit verschillende domeinen toonde aan dat er geen universele winnaar bestaat onder MT-systemen. Welk systeem het beste presteert, hangt sterk af van het specifieke taaldomein en het contenttype.
Kernbevinding: Een MT-systeem dat uitstekend presteert op juridische Nederlandse teksten kan middelmatig zijn voor Spaanse farmaceutische bijsluiters. Modelkeuze is domeinspecifiek, niet generiek.
Dit heeft directe praktische implicaties. Juridische teksten vereisen exacte terminologie met begrip van juridische context. Een AI-model dat “consideration” in een Engelstalig contract vertaalt naar het Nederlandse equivalent in verbintenissenrecht, moet begrijpen dat dit een technisch juridisch begrip is, geen gewone “overweging”. Medische content vereist nog meer precisie: de vertaling van contra-indicaties, bijwerkingprofielen en klinische eindpunten moet niet alleen terminologisch correct zijn, maar ook regelgevend compliant met de eisen van de EMA of nationale toezichthouders.
Het verschil tussen NMT en LLM voor compliance is op dit punt cruciaal. NMT-systemen vertalen statistisch, gebaseerd op patronen in trainingsdata. LLM-systemen begrijpen instructies en context. Dat betekent dat u een LLM kunt instrueren: “Gebruik altijd de term ‘geneesmiddel’ voor ‘medicament’ conform ons goedgekeurde glossarium.” Een NMT-systeem volgt deze instructie niet betrouwbaar. Een goed geconfigureerde LLM doet dat wel, consequent, over duizenden pagina’s.
De efficiëntie en precisie bij documentvertalingen zijn meetbaar beter wanneer terminologiedatabases en vertalingsgeheugens (Translation Memories) diep geïntegreerd zijn in het AI-systeem. Dit is een technisch onderscheid dat veel inkoopteams onderschatten bij de evaluatie van leveranciers.
Praktische toepassing in gereguleerde sectoren
De theorie is duidelijk. Hoe werkt vertrouwelijke AI-vertaling nu dagelijks in uw branche?
De integratie van beveiligde AI-vertaling in een organisatie vereist een gestructureerde aanpak. Improviseren leidt tot precies de fouten die u wilt vermijden: medewerkers die uit gemak toch een publieke tool gebruiken, of gevoelige documenten die via een onbeveiligd kanaal naar een externe vertaler worden gestuurd.
Een bewezen aanpak volgt deze stappen:
Dataclassificatie doorvoeren. Identificeer welke documentcategorieën als vertrouwelijk gelden en welke vertaalroute daarvoor is toegestaan. Niet alle teksten zijn even gevoelig; een persberichtvertaling heeft andere eisen dan een klinisch protocol.
Tool-whitelist vaststellen. Bepaal welke vertaaltools zijn goedgekeurd door IT, Legal en Compliance. Documenteer dit in een intern beleidsdocument en laat medewerkers dit bevestigen.
Terminologiedatabases aanleggen. Stel een goedgekeurd glossarium op voor elk domein. Zorg dat dit glossarium geïntegreerd is in het vertaalsysteem zodat consistentie automatisch wordt afgedwongen.
Audit trails inrichten. Elke vertaalopdracht moet traceerbaar zijn: wie heeft welk document wanneer laten vertalen, door welk systeem, en wie heeft de output gereviewd? Dit is essentieel voor compliance-audits.
SME-review verplicht stellen voor kritische documenten. Definieer vooraf welke documenttypen menselijke review door een vakexpert vereisen. Bijsluiters, contractbijlagen, regelgevingsdossiers: altijd. Interne communicatie met laag risico: eventueel niet.
Training voor medewerkers organiseren. Bewustwording is geen eenmalig event. Regelmatige training over databeveiliging en correcte tool-gebruik is onderdeel van een duurzame compliance-cultuur.
Periodieke evaluatie van leveranciers. Controleer jaarlijks of uw vertaalpartner nog voldoet aan de geldende certificeringen, waaronder ISO 27001, ISO 17100 en sectorspecifieke normen als ISO 13485 voor medische hulpmiddelen.
Veelgemaakte fouten in de praktijk zijn voorspelbaar maar vermijdbaar. Organisaties investeren in een beveiligde tool, maar vergeten medewerkers te trainen op het gebruik ervan. Resultaat: medewerkers gebruiken de publieke tool die ze kennen, simpelweg omdat die sneller toegankelijk is. Een tweede veelgemaakte fout is het gebruik van generieke AI zonder sectorspecifieke configuratie. Een LLM zonder geïntegreerde terminologiedatabase en zonder SME-review is voor gereguleerde sectoren nauwelijks beter dan een publieke NMT.
Onderzoek naar governance bij AI in gereguleerde sectoren bevestigt dat hybride en proprietary systemen superieur zijn aan publieke oplossingen, maar alleen wanneer ze correct zijn geconfigureerd en ingebed in een werkproces dat mensen en technologie verantwoord combineert.
De voordelen van AI-vertaling worden pas volledig gerealiseerd wanneer procesdiscipline en toolkeuze hand in hand gaan. Hetzelfde geldt voor compliance bij juridische vertaling: de beste technologie lost een gebrekkig werkproces niet op.
Pro-tip: Betrek uw compliance-afdeling actief bij de selectie van een vertaalleverancier. Laat hen de Data Processing Agreement (DPA) beoordelen en controleer of de leverancier bereid is een audit te ondersteunen. Een leverancier die hiervoor terugdeinst, is geen betrouwbare partner voor gereguleerde toepassingen.
Wat experts vaak vergeten over vertrouwelijke AI-vertaling
Er is iets wat in de meeste discussies over vertrouwelijke AI-vertaling onderbelicht blijft. De focus ligt bijna altijd op de technologie: welk model, welke encryptie, welk certificeringsniveau. Dat is begrijpelijk, want de technische keuzes zijn bepalend. Maar ze zijn niet voldoende.
Wij zien regelmatig dat organisaties investeren in uitstekende technologie en toch complianceproblemen ondervinden. De reden is consistent: menselijk gedrag wordt onderschat. Een medewerker die tijdsdruk ervaart, grijpt terug naar de vertrouwde publieke tool. Een projectmanager die de procedure niet goed kent, stuurt een vertrouwelijk document naar een niet-gewhiteliste vertaler. Een IT-afdeling die de tool installeert maar nalaat hem te integreren in de bestaande werkprocessen.
Technologie schept de voorwaarden voor veiligheid. Procesdiscipline en bewustwording realiseren die veiligheid daadwerkelijk.
Dit is precies waarom het AI+HUMAN model bij compliance zo krachtig is, niet alleen omdat het AI combineert met een menselijke expert voor kwaliteitscontrole, maar ook omdat het een werkproces vereist dat mensen centraal stelt. De vakexpert die een AI-vertaling reviewt, is niet alleen een vangnet voor terminologiefouten. Die persoon is ook de bewaker van de processtappen: is de juiste tool gebruikt, is de audit trail compleet, is de output in lijn met de geldende glossaria?
Blinde technologiefixatie leidt tot schijnveiligheid. We kennen gevallen waarbij een organisatie een ISO 27001-gecertificeerde vertaalomgeving had ingericht, maar waarbij medewerkers desondanks documenten kopieerden naar een WhatsApp-gesprek voor snelle informele “vertaling” door een tweetalige collega. De tool was veilig. Het werkproces was dat niet.
De meest duurzame beveiliging combineert drie elementen: de juiste technologie, een afdwingbaar werkproces en structurele bewustwordingstraining. Wie alleen in technologie investeert, bouwt een beveiligde kluis met een open raam ernaast.
Meer weten of direct veilige vertalingen inzetten?
Vertrouwelijke AI-vertaling is geen luxe voor gereguleerde sectoren, het is een operationele noodzaak. De combinatie van een proprietary LLM-omgeving, diep geïntegreerde terminologiedatabases en menselijke vakexperts is de enige aanpak die zowel snelheid als compliance-zekerheid biedt.
AD VERBUM heeft meer dan 25 jaar ervaring in het vertalen van hoogrisicodocumentatie voor Life Sciences, Legal, Finance en Manufacturing. De unieke aanpak bij AD VERBUM combineert een proprietary LLM-ecosysteem op EU-servers met een netwerk van meer dan 3.500 vakexperts, volledig gecertificeerd onder ISO 27001, ISO 17100, ISO 13485, GDPR en HIPAA. Of u nu professionele AI+HUMAN vertalingen zoekt voor farmaceutische dossiers, juridische contracten of technische handleidingen: AD VERBUM levert nauwkeurig, veilig en aantoonbaar compliant. Bezoek de startpagina van AD VERBUM voor meer informatie of neem contact op voor een vrijblijvende beveiligingsanalyse van uw huidige vertaalproces.
Veelgestelde vragen over vertrouwelijke AI-vertaling
Wat is het grootste risico bij AI-vertaling voor gevoelige documenten?
Het grootste risico is een datalek doordat tekst via publieke AI-tools op externe servers terechtkomt. Publieke AI is risicovol voor compliance, terwijl proprietary en hybride systemen aantoonbaar veiliger zijn voor gereguleerde sectoren.
Is er één AI-oplossing die altijd het beste presteert voor gereguleerde sectoren?
Nee. Geen universele MT-winnaar bestaat: prestaties verschillen per sector, taalcombinatie en type content, wat domeinspecifieke configuratie en menselijke validatie onmisbaar maakt.
Welke technologie komt er aan voor vertrouwelijke AI-vertaling?
Privacy-preserving MT en confidential computing zijn de meest veelbelovende innovaties, waarbij verwerking plaatsvindt in beveiligde enclaves zonder dat de brondata ooit onversleuteld toegankelijk is voor externe partijen.
Waarom is menselijke controle nog steeds nodig bij AI-vertaling?
Zelfs de meest geavanceerde LLM kan een terminologiefout maken of een regelgevingseis missen die een vakexpert direct herkent. Menselijke controle is het verschil tussen een plausibel klinkende vertaling en een juridisch afdwingbare, compliant vertaling.
Hoe kan ik onze organisatie compliant houden bij AI-vertaling?
Gebruik uitsluitend proprietary of hybride beveiligde tools met aantoonbare certificeringen, leg audit trails vast voor elke vertaalopdracht, en train medewerkers structureel op het correcte gebruik van goedgekeurde werkprocessen.
Aanbeveling