
Slik sikrer du dataintegritet i AI-språktjenester
- 24. apr.
- 7 min lesing

De fleste som innfører AI-drevne språktjenester i regulerte virksomheter, antar at datasikkerhet og dataintegritet er det samme. De er det ikke. Og den misforståelsen kan koste virksomheten din dyrt. Språkmodeller er ikke designet for å unngå lekkasje av sensitiv informasjon uten spesielle tiltak, og det betyr at standard AI-verktøy kan skape compliance-brudd som ingen brannmur kan forhindre. Denne artikkelen gir deg en strukturert gjennomgang av hva dataintegritet faktisk krever i AI-språktjenester, hvilke trusler som er mest undervurderte, og hvilke metoder som faktisk fungerer i praksis.
Innholdsfortegnelse
Viktige Funn
Punkt | Detaljer |
Dataintegritet er mer enn sikkerhet | Det sikrer at data forblir uforandret og ikke lekker under språkbehandling. |
Risiko finnes i modellminne | AI-modeller kan lagre sensitiv informasjon som er vanskelig å fjerne. |
Flere lag med kontroll er nødvendig | Defense-in-depth bruker blanding av teknologiske og manuelle tiltak. |
Compliance krever sporbarhet | Audit trails og dokumentert etterlevelse er essensielt for revisjon. |
Forebygging slår alltid reparasjon | Proaktive tiltak og tydelige rutiner gir størst trygghet mot datasvikt. |
Hva betyr dataintegritet i språktjenester?
For å forstå hvilke utfordringer og løsninger som finnes, må vi først vite hva dataintegritet faktisk betyr i denne sammenhengen.
Datasikkerhet handler om å beskytte data mot uautorisert tilgang. Brannmurer, kryptering og tilgangskontroll er typiske tiltak. Dataintegritet er noe annet og langt mer krevende. Det handler om at data forblir korrekte, fullstendige og upåvirkede gjennom hele livssyklusen, inkludert under oversettelse og lokalisering.
I konteksten av AI-drevne språktjenester får dataintegritet i oversettelser en ekstra dimensjon. En LLM-modell som brukes til å oversette kliniske studier, juridiske kontrakter eller finansrapporter, kan utilsiktet memorere sensitiv informasjon og gjengi den i fremtidige outputs. Det kalles modell-minne, og det er et av de mest undervurderte risikoelementene i bransjen.

For farmasi, finans og teknologi er konsekvensene av integritetssvikt sjelden reversible. En feil i et medikament-datasett som oversettes og distribueres til klinisk bruk, kan i verste fall true pasientsikkerhet. En ukorrekt oversettelse av en risikoklausul i en finanskontrakt kan utløse juridisk ansvar. Det er ikke teoretiske scenarioer. De er reelle eksempler på hva integritetssvikt koster.
Forskning peker på at avidentifisering og syntetiske data er kjerneprinsipper for bedre dataintegritet i AI-systemer. Men svært få språktjenesteleverandører implementerer dette i praksis.
Hvorfor holder ikke tradisjonelle tiltak? Fordi de er bygget for et annet trussellandskap. Integritetskravene i regulerte bransjer krever nå:
Sporbarhet for hvert oversettelsesledd
Kontrollert terminologihåndtering uten avvik
Garantert isolasjon av tredjepartsdata
Dokumentert samsvar med GDPR, HIPAA og MDR
“Dataintegritet er ikke en funksjon du aktiverer. Det er en prosess du kontinuerlig vedlikeholder.”
Fellesnevneren for svikt er ikke mangel på teknologi. Det er mangel på struktur. Og det er her forståelse av data integrity og AI blir avgjørende for ledere som tar compliance på alvor.
Typiske trusler mot dataintegritet i AI-språktjenester
Etter å ha forstått behovet for dataintegritet, er det avgjørende å kjenne igjen de største truslene.
De mest alvorlige truslene er ikke de mest åpenbare. Mange virksomheter fokuserer på ytre trusler som hackere eller driftsforstyrrelser. Men de farligste sårbarhetene i AI-språktjenester er innebygde i selve teknologien.
De fem vanligste truslene er:
Modell-minne og re-identifikasjon: Offentlige NMT-verktøy kan lagre og gjenbruke data fra tidligere sesjoner. Sensitiv pasientinformasjon eller forretningshemmeligheter kan dukke opp i andres output.
Utilstrekkelig anonymisering: Partielle anonymiseringstiltak gir falsk trygghet. En enkelt gjenværende identifikator kan gjøre hele datasettet identifiserbart.
Hallusinasjoner i oversettelse: NMT-motorer kan generere fluent tekst som utelater negasjoner eller endrer fakta uten varsel. “Ikke-toksisk” kan bli “toksisk”.
Manglende audit trail: Uten dokumentasjon på hvert prosesseringsledd er det umulig å spore feil til kilden, noe som gjør compliance-revisjon umulig.
Uklarhet om datalagring: Mange leverandører er uklare på om og hvor lenge data lagres etter oversettelse.
GDPR, AI Act og HIPAA-krav til AI pålegger krav som er vanskelige for standard AI å oppfylle fullt ut, særlig på grunn av innbakt modell-minne og manglende kontroll over treningsdata. For GDPR for språktjenester er dette spesielt kritisk: retten til å bli glemt kan ikke oppfylles dersom data allerede er absorberte i en modell.
Tall å kjenne til: Regelverksbrudd knyttet til AI og personvern resulterte i bøter på over 1,6 milliarder euro i Europa i 2023 alene.
Det handler ikke bare om juridisk risiko. Det handler om tillit. Kunder, pasienter og myndigheter forventer at din virksomhet kontrollerer dataflytene sine.
Proffetips: Krev en skriftlig databehandleravtale og en detaljert forklaring på datalagring fra alle leverandører av data-sikkerhet i oversettelse før du signerer noen kontrakt.
Metoder for å sikre dataintegritet: fra avidentifisering til audit trail
Når vi kjenner truslene, trenger vi en sikkerhetsramme bygget på flere nivåer.
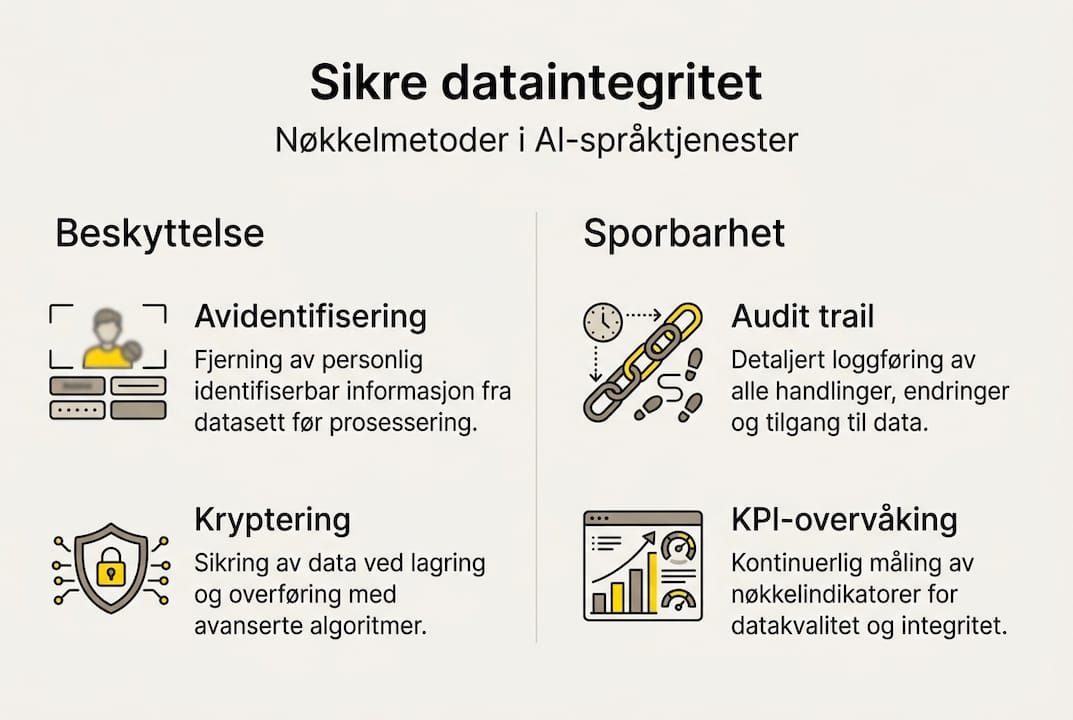
En enkelt løsning eksisterer ikke. Det som fungerer er det eksperter kaller defense-in-depth: flernivå-tilnærming er avgjørende for dataintegritet i AI-systemer. Det betyr at hvert ledd i dataflyten har egne kontroller, og at svikt i ett ledd ikke kompromitterer hele systemet.
De viktigste metodene er:
Avidentifisering og syntetisering før prosessering: Fjern eller erstatt identifiserbare elementer før data sendes til AI-motoren. Syntetiske data etterligner originalen uten å eksponere ekte informasjon.
Sikre pipelines og kryptering: Data under transport skal krypteres ende-til-ende. Private cloud-miljøer forhindrer at data eksponeres mot offentlige tjenester.
Post-prosessering og manuell verifisering: En fagekspert (SME) gjennomgår output for terminologisk nøyaktighet og faktakontroll, ikke bare språklig kvalitet.
Audit trail: Hvert steg i oversettelsesprosessen dokumenteres med tidsstempler og ansvarlig part.
Metode | Styrke | Begrensning |
Avidentifisering | Reduserer eksponering markant | Krever kompetanse og ressurser |
Syntetiske data | Ivaretar mønster uten risiko | Kan miste kontekstuell nyanser |
Kryptering under transport | Hindrer avlytting | Beskytter ikke mot interne feil |
Manuell SME-revisjon | Fanger kontekstuelle feil | Tidkrevende uten riktig struktur |
Audit trail | Muliggjør full sporbarhet | Krever systematisk implementering |
Proffetips: Bruk sikre språktjenester som allerede har integrert disse metodene i sin standardprosess. Det er raskere og sikrere enn å bygge det fra bunnen internt.
For virksomheter som ønsker å starte, er en datasikker oversettelse ikke et engangstiltak. Det er en løpende prosess som bør dokumenteres mot en compliance sjekkliste tilpasset din bransje og ditt rammeverk.
Praktisk anvendelse: implementering av dataintegritet i språktjenester
Med metodene kartlagt, kan virksomheter begynne å implementere konkrete tiltak.
Det første steget er en risikoanalyse. Ikke generisk, men spesifikk for din virksomhets datatyper, kontraktsforpliktelser og regulatoriske krav. En farmasibedrift har andre risikoer enn en finansinstitusjon, selv om begge opererer under strenge regimer.
Implementeringsprosessen bør følge denne rekkefølgen:
Kartlegg dataflyten: Identifiser nøyaktig hvilke data som berøres av språktjenester, fra kilde til endelig output.
Risikovurder leverandøren: Still konkrete krav til datalagring, isolasjon og sertifiseringer. ISO 27001, GDPR og HIPAA er minimumskrav.
Implementer pre-prosessering: Innfør avidentifisering som standardprosedyre før data sendes til oversettelse.
Definer terminologipolicy: Opprett godkjente termbaseser og Translation Memories som leverandøren er forpliktet til å bruke.
Krav til audit trail: Sørg for at leverandøren kan levere fullstendig dokumentasjon per prosjekt.
Revider regelmessig: Dataintegritetstiltak foreldes. Kvartalsvise gjennomganger er minimumsstandard.
Et viktig poeng som ofte overses: Data i LLM er vanskelig å fjerne etter trening. Fullstendig sletting krever re-trening av hele modellen. Det gjør forebygging langt mer verdifullt enn reparasjon.
KPI | Målemetode | Akseptabelt nivå |
Terminologiavvik | Automatisk QA-sjekk | Under 0,5 % per dokument |
Audit trail-dekning | Prosjektlogg | 100 % av alle leveranser |
Anonymiseringsrate | Pre-prosesseringsrapport | 100 % av sensitiv data |
Leverandørsertifisering | Årlig verifisering | ISO 27001 + GDPR gyldig |
For regulert dokumentarbeidsflyt bør disse KPI-ene inngå i leverandørkontrakten. Og når du velger en partner, er AI+HUMAN for regulerte språktjenester den eneste modellen som gir deg både hastighet og menneskelig fagkontroll i ett og samme løp.
Hva de fleste misforstår om dataintegritet i AI-drevne språktjenester
Den vanligste feilen ledere gjør er å likestille sertifisering med sikkerhet. En leverandør med ISO 27001 har bevist at de har et informasjonssikkerhetssystem. Det betyr ikke at din konkrete dataflyten er ivaretatt uten feil.
Teknisk compliance er en minimumsterskel, ikke en garanti. De virkelige sårbarhetene oppstår i gapet mellom det leverandøren hevder å gjøre og det de faktisk gjør i operasjonell praksis. Det er her “unknown unknowns” lever: prosedyrer som aldri ble testet under reelle arbeidsforhold, anonymiseringsrutiner som feiler ved uventede dataformater, eller audit trail-systemer som kun er aktive på forespørsel.
Erfaringen viser at egne ansatte ofte er et svakere ledd enn teknologien. En medarbeider som kopierer sensitiv tekst inn i et offentlig NMT-verktøy fordi det er raskere, kan undergrave hele virksomhetens datasikkerhet i oversettelse. Opplæring og intern policy er ikke “nice to have”. De er kjernen i et fungerende integritetssystem.
Den ubehagelige sannheten er at dataintegritet ikke er noe du implementerer én gang. Det er noe du kontinuerlig vedlikeholder, tester og reviderer. Leverandørvalg er kritisk, men det er bare startpunktet.
Slik kan du enkelt styrke dataintegritet i egne språktjenester
For virksomheter som ikke kan risikere feil, er valget av språktjenestepartner avgjørende for faktisk compliance.
AD VERBUM leverer AI-drevne språktjenester på en proprietær LLM-plattform hostet utelukkende på EU-servere, uten eksponering mot offentlige sky-tjenester. Vår AI+HUMAN arbeidsmodell kombinerer avidentifisering, sikre pipelines, full audit trail og manuell fagkontroll fra over 3 500 fagspesialiserte lingvister. Alle innovative sikkerhetsfunksjoner er integrert i standardleveransen, ikke valgfrie tillegg. Utforsk våre oversettelsestjenester og ta kontakt for en uforpliktende gjennomgang av din virksomhets spesifikke behov.
Ofte stilte spørsmål
Hva skiller dataintegritet fra datasikkerhet i språktjenester?
Datasikkerhet handler om å beskytte mot eksterne trusler, mens dataintegritet sikrer at data ikke endres, mistolkes eller lekker under språktjenester. Dataintegritet ivaretas gjennom avidentifisering og kontinuerlig revisjon, ikke bare tekniske barrierer.
Er det mulig å fjerne sensitiv informasjon helt fra AI-modellene?
Fullstendig sletting fra LLM-modeller er sjelden mulig uten re-trening av hele modellen, noe som gjør forebyggende datahåndtering langt mer avgjørende enn korrektive tiltak i etterkant.
Hvilke lover påvirker dataintegritet i AI-språktjenester?
GDPR, AI Act og HIPAA krever anonymisering, dataminimering og sporbarhet for alle sensitive data. GDPR, AI Act og HIPAA stiller krav som standard AI-verktøy ikke kan oppfylle uten spesialiserte tiltak.
Hva er defense-in-depth for språktjenester?
Det betyr at man bruker flere lag med sikkerhet og kontroll i hele dataflyten: pre-prosessering, sikre systemer og revisjon. Flernivå-tilnærming er avgjørende fordi svikt i ett enkelt lag ikke kompromitterer hele systemet.
Anbefaling


