
Rol van LLM in vertaalprocessen: precisie en compliance 2026
- 19 mrt
- 8 minuten om te lezen

In gereguleerde sectoren zoals levenswetenschappen, juridisch en financieel is elke vertaalfout een potentieel compliance-risico. Traditionele vertaalmethoden worstelen met de complexiteit van technische documentatie, waar één verkeerd gekozen term een patiëntveiligheidsincident of juridische aansprakelijkheid kan veroorzaken. LLMs transformeren vertaalprocessen met technieken als few-shot prompting, parameter-efficient fine-tuning en synthetische data generatie, wat nieuwe mogelijkheden biedt voor precisie. Dit artikel verkent hoe deze geavanceerde taalmodellen de vertaalworkflow verbeteren, welke beperkingen ze hebben, en waarom menselijk toezicht cruciaal blijft. U ontdekt concrete inzichten over technische methoden, prestaties in juridische context, en veilige implementatie in compliance workflows.
Inhoudsopgave
Belangrijkste inzichten over de rol van LLM in vertaalprocessen
Point | Details |
Geavanceerde technieken | LLMs gebruiken few-shot prompting en cross-lingual transfer voor nauwkeurige vertalingen, zelfs bij beperkte trainingsdata. |
Specialistische modellen | Sectorgerichte fine-tuning maakt LLMs effectief voor juridische, medische en financiële documentatie met hoge precisie-eisen. |
Menselijke controle essentieel | In gereguleerde sectoren blijft human-in-loop toezicht noodzakelijk om compliance te waarborgen en hallucinaties te voorkomen. |
Risico-detectie | Synthetische data helpt vertaalfouten en terminologieproblemen proactief op te sporen, wat efficiëntie verhoogt. |
Afweging literaliteit | LLMs balanceren tussen woordelijke nauwkeurigheid en contextuele creativiteit, afhankelijk van documenttype en sector. |
Technische basis en methoden van LLM in vertaalprocessen
De kracht van LLMs in vertaling ligt in hun vermogen om context te begrijpen en instructies te volgen. In tegenstelling tot oudere systemen die woord voor woord vertalen, analyseren LLMs complete zinnen en documenten om betekenis te behouden. Deze fundamentele verschuiving maakt ze geschikt voor complexe, gereguleerde documentatie.
Few-shot prompting is een doorbraak voor talen met beperkte trainingsdata. U geeft het model enkele voorbeelden van correcte vertalingen, waarna het deze patronen toepast op nieuwe tekst. Cross-lingual transfer bouwt hierop voort door kennis van talen met veel data over te dragen naar talen met weinig beschikbare bronnen. Dit verkleint de kloof tussen veelgebruikte en minder gangbare talen aanzienlijk.
Parameter-efficient fine-tuning, zoals LoRA (Low-Rank Adaptation), stelt u in staat modellen te specialiseren zonder volledige hertraining. Deze techniek past slechts een fractie van de modelparameters aan, wat rekenkracht bespaart en overfitting voorkomt. Voor sectoren met strikte terminologie betekent dit dat u LLMs kunt afstemmen op uw specifieke woordenschat zonder de algemene taalkennis te verliezen.
Synthetische data generatie lost een kritiek probleem op: gebrek aan parallelle teksten voor gespecialiseerde domeinen. Back-translation creëert nieuwe trainingsvoorbeelden door tekst heen en weer te vertalen tussen talen. Lexicale augmentatie vervangt woorden met synoniemen uit uw terminologiedatabase. Deze methoden vergroten de dataset zonder handmatige annotatie, wat kosten verlaagt en consistentie verbetert.
De combinatie van deze technieken zorgt voor nauwkeurigheid die traditionele machinevertaling niet kan evenaren. LLMs begrijpen dat “dispositif” in een Frans medisch patent “hulpmiddel” betekent, niet “apparaat”, gebaseerd op de volledige documentcontext. Ze volgen uw glossary-instructies strikt, wat cruciaal is voor compliance.
Pro-tip: optimaliseer uw fine-tuning door eerst een kleine subset van hoogwaardige, domein-specifieke vertalingen te selecteren. Test het model incrementeel en pas de trainingsparameters aan op basis van prestaties op validatiedata. Dit voorkomt verspilling van rekenkracht en levert sneller een bruikbaar model op.
De technische verfijning van LLMs maakt ze tot een betrouwbare basis voor vertaalprocessen in sectoren waar fouten geen optie zijn. Het begrijpen van deze onderliggende methoden helpt u weloverwogen beslissingen te nemen over implementatie en kwaliteitscontrole.
Prestaties en beperkingen van open LLMs in juridische en compliance vertalingen
Recente benchmarks tonen dat open LLMs sterke prestaties leveren op standaard vertaaltaken. Modellen zoals LLaMA3 en Mistral scoren hoog op WMT-24 en FLORES-200 datasets, met indrukwekkende resultaten voor 28 talen. Deze prestaties maken ze aantrekkelijk voor organisaties die controle willen over hun vertaalinfrastructuur.
Echter, juridische en compliance documentatie stelt unieke eisen. Een contract vereist absolute literaliteit, waar een marketingtekst ruimte laat voor creatieve aanpassingen. Open LLMs excelleren in algemene vertaling maar worstelen soms met de nuances van juridisch jargon. De XCOMET en COMETKiwi metrics meten vertaalkwaliteit, maar vangen niet altijd de subtiele betekenisverschillen die juridische aansprakelijkheid bepalen.

Hallucinatierisico’s vormen een serieuze bedreiging in gereguleerde contexten. LLMs kunnen met overtuiging onjuiste informatie genereren, vooral in laagresource talen of bij complexe technische terminologie. Een model kan “non-toxique” vertalen als “toxisch” door de negatie te missen, wat in farmaceutische documentatie catastrofale gevolgen heeft. Zelf-bias, waarbij het model zijn eigen eerdere output verkiest boven correcte alternatieven, versterkt deze fouten.
Veelvoorkomende beperkingen in praktische vertalingssituaties:
Inconsistente terminologie over lange documenten, zelfs met expliciete glossary-instructies
Verlies van juridische precisie bij idiomatische uitdrukkingen of clausules met meerdere interpretaties
Onvermogen om culturele of jurisdictie-specifieke nuances te herkennen zonder uitgebreide context
Moeilijkheden met tabellen, voetnoten en andere gestructureerde elementen in complexe contracten
Neiging tot over-simplificatie van technische passages om leesbaarheid te verbeteren
De volgende tabel vergelijkt benchmark scores van relevante open LLMs op basis van recente evaluaties:
Model | XCOMET Score | COMETKiwi Score | Talen |
LLaMA3-70B | 0.847 | 0.823 | 28 |
Mistral-7B | 0.831 | 0.809 | 24 |
Qwen2-72B | 0.852 | 0.828 | 30 |
Gemma-27B | 0.839 | 0.815 | 26 |
Deze scores reflecteren algemene vertaalkwaliteit, maar vertellen niet het hele verhaal voor juridische vertaaldiensten. Een model met een hoge XCOMET score kan nog steeds kritieke fouten maken in contractclausules of compliance-gerelateerde passages. De metrics meten vooral fluency en adequacy, niet de juridische correctheid die uw sector vereist.
Mitigatie van hallucinaties vereist een meerlagige aanpak. Constrain het model met strikte instructies en voorbeelden. Gebruik retrieval-augmented generation om het model toegang te geven tot uw goedgekeurde terminologiedatabase tijdens vertaling. Implementeer automatische consistency checks die flaggen wanneer dezelfde term verschillend wordt vertaald binnen één document.
De realiteit is dat open LLMs krachtige tools zijn, maar geen kant-en-klare oplossing voor compliance-kritische vertalingen. Ze vereisen zorgvuldige configuratie, domein-specifieke fine-tuning, en vooral robuuste menselijke controle om hun potentieel veilig te benutten.
Toepassing en compliance: LLMs in vertaalworkflows voor levenswetenschappen, financiële en juridische sector
In gereguleerde sectoren is human-in-loop toezicht niet optioneel, het is een compliance-vereiste. LLMs genereren de eerste vertaling snel, maar een gecertificeerde vertaler met domeinexpertise moet elke regel verifiëren. Deze expert controleert niet alleen taalkundige correctheid, maar ook of de vertaling voldoet aan sectorspecifieke regelgeving en terminologiestandaarden.
Veilige integratie van LLMs in compliance workflows volgt een gestructureerd proces:
Begin met een risicoanalyse per documenttype om te bepalen welke vertalingen LLM-ondersteuning kunnen gebruiken
Implementeer strikte toegangscontroles en audit trails voor alle vertaalactiviteiten met gevoelige data
Configureer het LLM met uw goedgekeurde terminologiedatabase en style guides voordat u begint
Laat het model een concept genereren, maar blokkeer directe publicatie zonder menselijke review
Voer een dubbele controle uit door een tweede expert voor kritieke documenten zoals klinische trial protocols
Documenteer alle wijzigingen die de menselijke vertaler aanbrengt om het model te verbeteren
Bewaar volledige versiegeschiedenis voor compliance audits en traceerbaarheid
Een concreet voorbeeld uit de farmaceutische sector illustreert deze aanpak. Het PhT-LM model, speciaal getraind op medische literatuur, vertaalt klinische documentatie met hoge nauwkeurigheid. Het herkent dat “adverse event” in patiëntinformatie anders vertaald moet worden dan in een regulatory submission. Toch controleert een medisch vertaler met farmaceutische achtergrond elke vertaling op compliance met EMA en FDA guidelines.
Pro-tip: combineer LLMs met gespecialiseerde menselijke vertalers door een hybride workflow te creëren. Laat het LLM repetitieve, goed gedefinieerde secties vertalen, zoals standaard disclaimers of productspecificaties. Reserveer menselijke expertise voor complexe passages met juridische implicaties of klinische interpretatie. Dit maximaliseert efficiëntie zonder veiligheid te compromitteren.
Synthetische data speelt een sleutelrol in proactieve foutdetectie. U genereert varianten van uw documentatie met bekende fouten, zoals ontbrekende negaties of verkeerde eenheden. Train een tweede model om deze fouten te herkennen in LLM-output. Dit early warning systeem vangt problemen op voordat ze menselijke reviewers bereiken, wat tijd bespaart en risico’s vermindert.
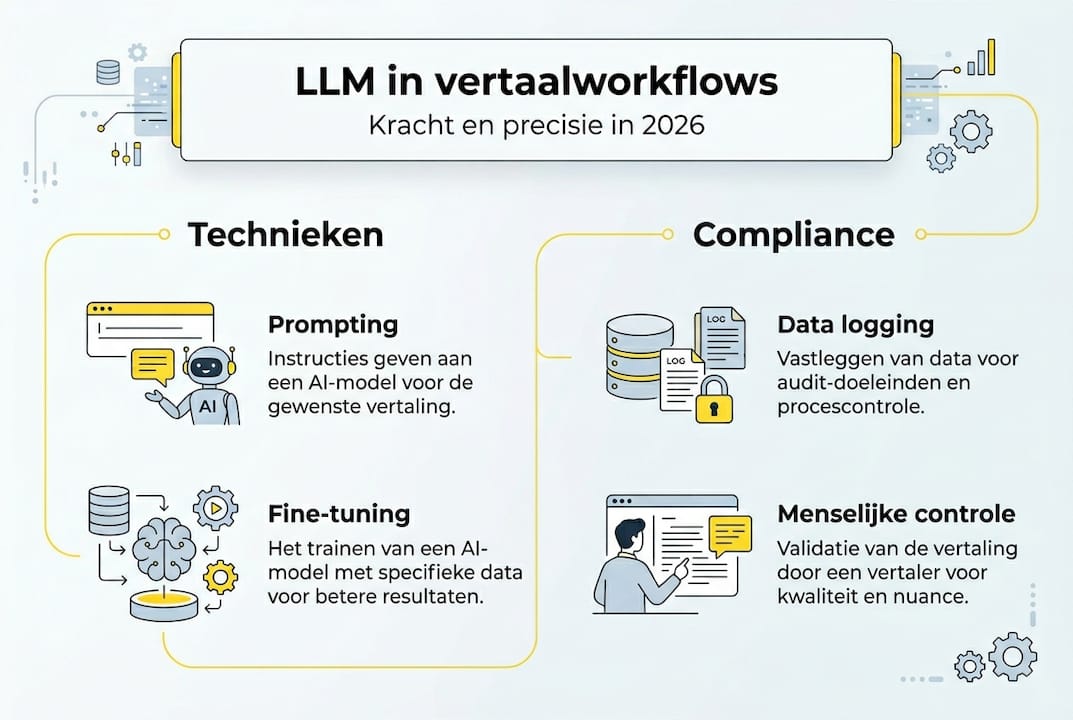
De workflow voor veilige AI-vertaling in uw sector vereist ook technische beveiliging. Host het LLM op private servers binnen uw jurisdictie om data sovereignty te waarborgen. Encrypteer alle documenten in transit en at rest. Implementeer role-based access control zodat alleen geautoriseerd personeel gevoelige vertalingen kan inzien. Deze maatregelen beschermen intellectueel eigendom en patiëntgegevens tegen ongeautoriseerde toegang.
Compliance documentatie voor audits moet aantonen dat uw vertaalproces betrouwbaar is. Log elke LLM-interactie met timestamps, gebruikers-ID en documentidentificatie. Bewaar de originele LLM-output naast de door mensen herziene versie. Dit creëert een audit trail die regelgevers kunnen inspecteren om te verifiëren dat uw proces voldoet aan kwaliteitsnormen.
De praktische toepassing van LLMs in uw sector balanceert innovatie met voorzichtigheid. U profiteert van snelheid en schaalbaarheid, terwijl menselijke expertise de laatste verdedigingslinie vormt tegen fouten die compliance en veiligheid bedreigen.
Ontdek hoe AD VERBUM u ondersteunt in veilige en nauwkeurige vertalingen
De complexiteit van LLM-gebaseerde vertaling in gereguleerde sectoren vereist een partner die technologie en compliance begrijpt. AD VERBUM combineert geavanceerde LLM-technologie met rigoureus menselijk toezicht in een AI+HUMAN workflow die specifiek is ontworpen voor levenswetenschappen, juridische en financiële documentatie.
Onze vertalingsdiensten integreren uw bestaande Translation Memories en terminologiedatabases in een proprietary LLM-ecosysteem, gehost op EU-servers voor volledige data sovereignty. Elk document doorloopt een gestructureerd proces: LLM-generatie met strikte terminologie-enforcement, gevolgd door verificatie door een Subject Matter Expert met domeinkennis in uw sector. Deze aanpak waarborgt dat elke vertaling voldoet aan ISO 17100, ISO 18587 en sectorspecifieke standaarden zoals MDR voor medische hulpmiddelen.
Met 25 jaar ervaring en certificeringen voor ISO 27001, GDPR en HIPAA, begrijpen we dat precisie in uw sector niet onderhandelbaar is. Onze AI-vertaling levert 3x tot 5x snellere doorlooptijden zonder concessies aan nauwkeurigheid, ondersteund door een netwerk van 3.500+ gespecialiseerde vertalers. Ontdek hoe we uw vertaalworkflow kunnen optimaliseren met de veiligheid en compliance die uw sector vereist.
Veelgestelde vragen over de rol van LLM in vertaalprocessen
Welke risico’s brengen LLMs mee voor compliance in vertalingen?
LLMs kunnen hallucinaties genereren waarbij ze onjuiste informatie met overtuiging presenteren, vooral bij complexe terminologie. In juridische of medische context kan een gemiste negatie of verkeerde term leiden tot compliance-schendingen of veiligheidsrisico’s. Data leakage is een ander risico als u publieke LLM-diensten gebruikt voor gevoelige documentatie, wat GDPR en HIPAA overtredingen veroorzaakt.
Hoe waarborg ik data-integriteit bij AI-ondersteunde vertalingen?
Implementeer een private LLM-infrastructuur op servers binnen uw jurisdictie, met end-to-end encryptie voor alle documenten. Gebruik strikte toegangscontroles en audit trails die elke vertaalactie loggen. Integreer uw goedgekeurde terminologiedatabase direct in het model om consistentie af te dwingen. Laat altijd een menselijke expert de output verifiëren voordat publicatie.
Wat is het belang van menselijke controle bij LLM-gebruik?
Menselijke experts herkennen contextuele nuances en culturele subtiliteiten die LLMs missen. Ze verifiëren dat vertalingen voldoen aan sectorspecifieke regelgeving en terminologiestandaarden. In compliance-kritische vertaling fungeert de menselijke vertaler als laatste verdedigingslinie tegen fouten die juridische of veiligheidsconsequenties hebben.
In welke sectoren zijn LLMs het meest effectief voor vertalingen?
LLMs excelleren in sectoren met grote volumes technische documentatie en gestandaardiseerde terminologie, zoals levenswetenschappen, financiële diensten en juridisch. Ze zijn vooral effectief voor repetitieve content zoals productspecificaties, standaard contractclausules en reguliere rapportages. Voor creatieve of sterk cultureel gebonden content blijft menselijke vertaling superieur.
Hoe voorkomt u hallucinaties in vertalingen met LLMs?
Constrain het model met expliciete instructies en voorbeelden van correcte vertalingen. Gebruik retrieval-augmented generation om het model real-time toegang te geven tot uw terminologiedatabase. Implementeer automatische consistency checks die flaggen wanneer dezelfde term verschillend wordt vertaald. Train een tweede model op synthetische data met bekende fouten om problematische output te detecteren voordat menselijke review.
Wat zijn de voordelen van parameter-efficient fine-tuning voor mijn organisatie?
Parameter-efficient fine-tuning zoals LoRA past slechts een fractie van modelparameters aan, wat rekenkracht en kosten bespaart. U kunt het model specialiseren op uw specifieke terminologie en documentstijl zonder de algemene taalkennis te verliezen. Dit maakt frequente updates mogelijk wanneer uw terminologie evolueert, zonder volledige hertraining die weken duurt en aanzienlijke resources vereist.
Aanbeveling


